Если вы просто ищете парсер OLX и не хотите учиться написанию парсеров, вы можете просто загрузить готовый парсер OLX.UA или OLX.KZ в ваш аккаунт на платформе Diggernaut из нашего каталога бесплатных парсеров
Наверное многие знают, что такое доска объявлений OLX. В России компания была поглощена Авито. Однако OLX до сих пор существует во многих других странах: Украине, Польше, Казахстане и многих других. С полным списком стран можно ознакомиться на основном сайте OLX.
Изменено 1 февраля 2020, добавлена логика переключения прокси при блокировке
Так как все сайты OLX как правило построены на фреймворке одной серии, то парсер, который мы напишем сможет теоретически работать с сайтом в любой стране. Могут быть конечно исключения, но как правило все должно будет работать. Поэтому мы возьмем за основу OLX Украины, а после того как парсер у нас будет готов, протестируем его так же на других сайтах.
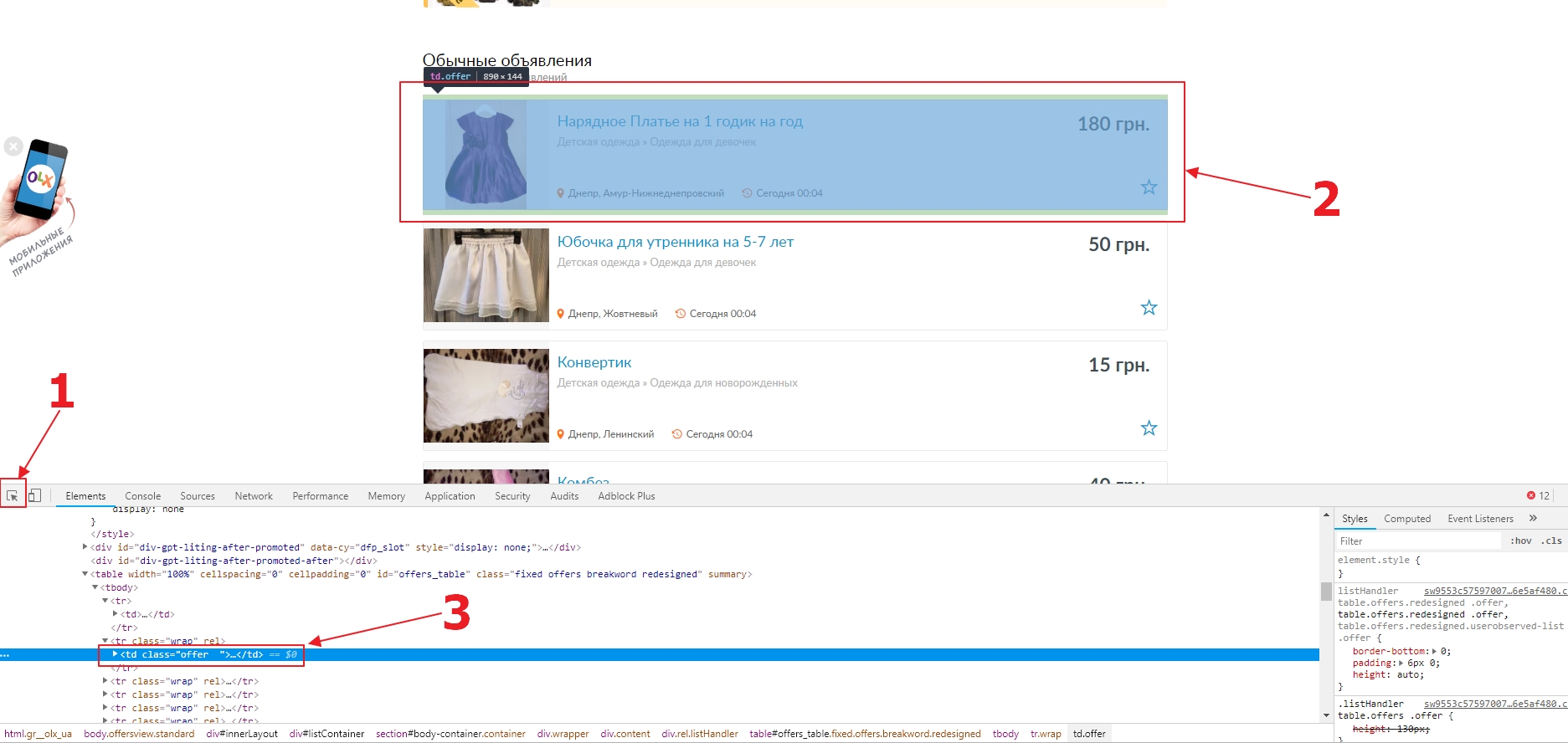
Итак, начнем мы с каталога. Разберемся как работает навигация между страницами одного раздела. Найдем где брать ссылки на страницы с конкретным объявлением. Выберем случайную категорию: Детская одежда. Откроем страницу в Chrome, и включим инструменты разработчика. Перейдем во вкладку Elements, и выберем инструмент для инспектирования элемента на странице (1). Кликнем в интересующий нас блок с первым товаром в списке (2), после чего, в HTML вкладке Elements, отметится нужный нам элемент (3).
{kind=link}
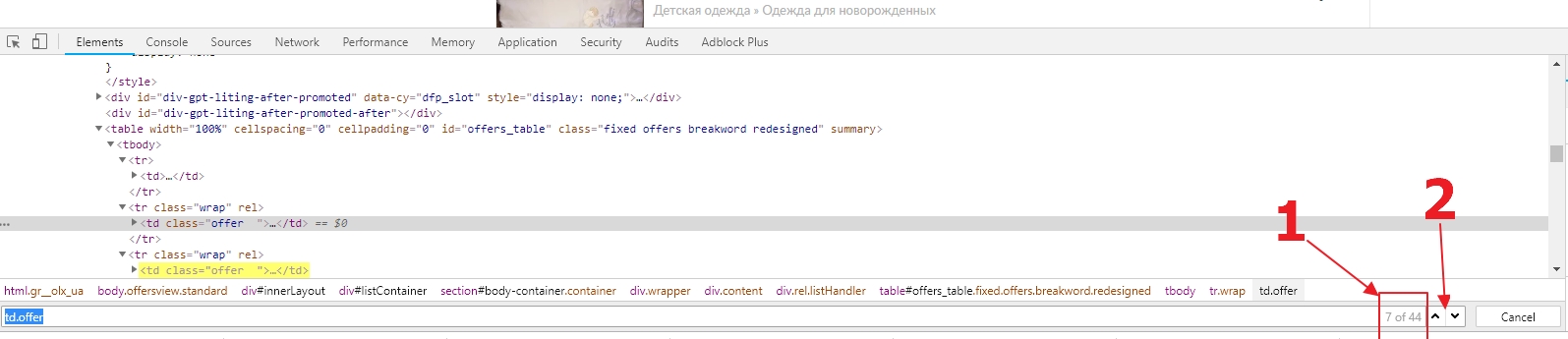
Возможно, мы сможем использовать CSS селектор td.offer для выбора блока, но сначала надо в этом убедиться. Для этого нажмем CTRL+ F, находясь в HTML коде вкладки Elements. Введем наш селектор в строку поиска. Если вы все сделали правильно, то вы увидите, что найдено 44 элемента (1). Чтобы проверить не забрал ли селектор чего лишнего, просто используйте кнопки вверх-вниз (2) и посмотрите, что за элементы выбраны. Если вы хотите исключить объявления в топе (которые продвигаются за деньги), можно использовать такой селектор: td.offer:not(.promoted).
{kind=link}
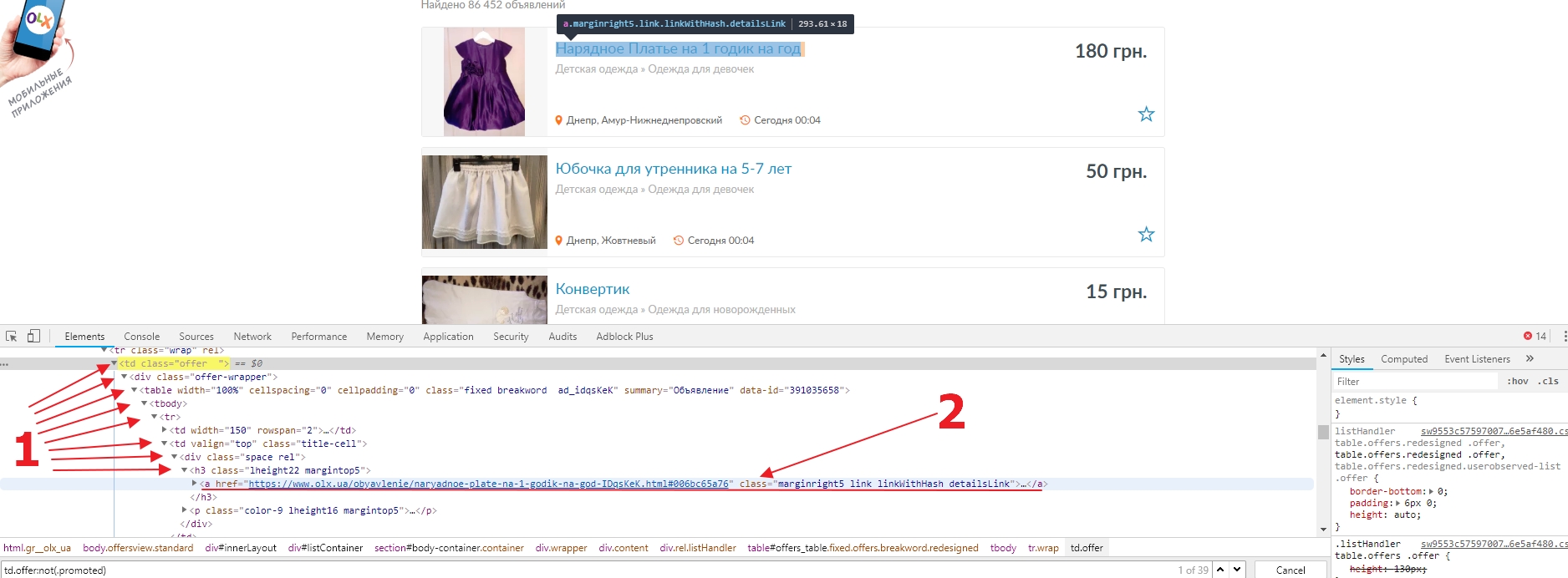
Однако нам нужен не сам блок, а ссылка на страницу объявления. Поэтому раскроем HTML элемента (1) и найдем то, что нас интересует (2). Таким образом наш селектор для ссылок на страницы объявлений будет td.offer a.link.detailsLink. Проверяем и удостоверяемся, что ссылок ровно 44. В разных версиях OLX может быть различное форматирование блоков с объявлениями, поэтому мы можем использовать селектор a.link.detailsLink для большей совместимости.
{kind=link}
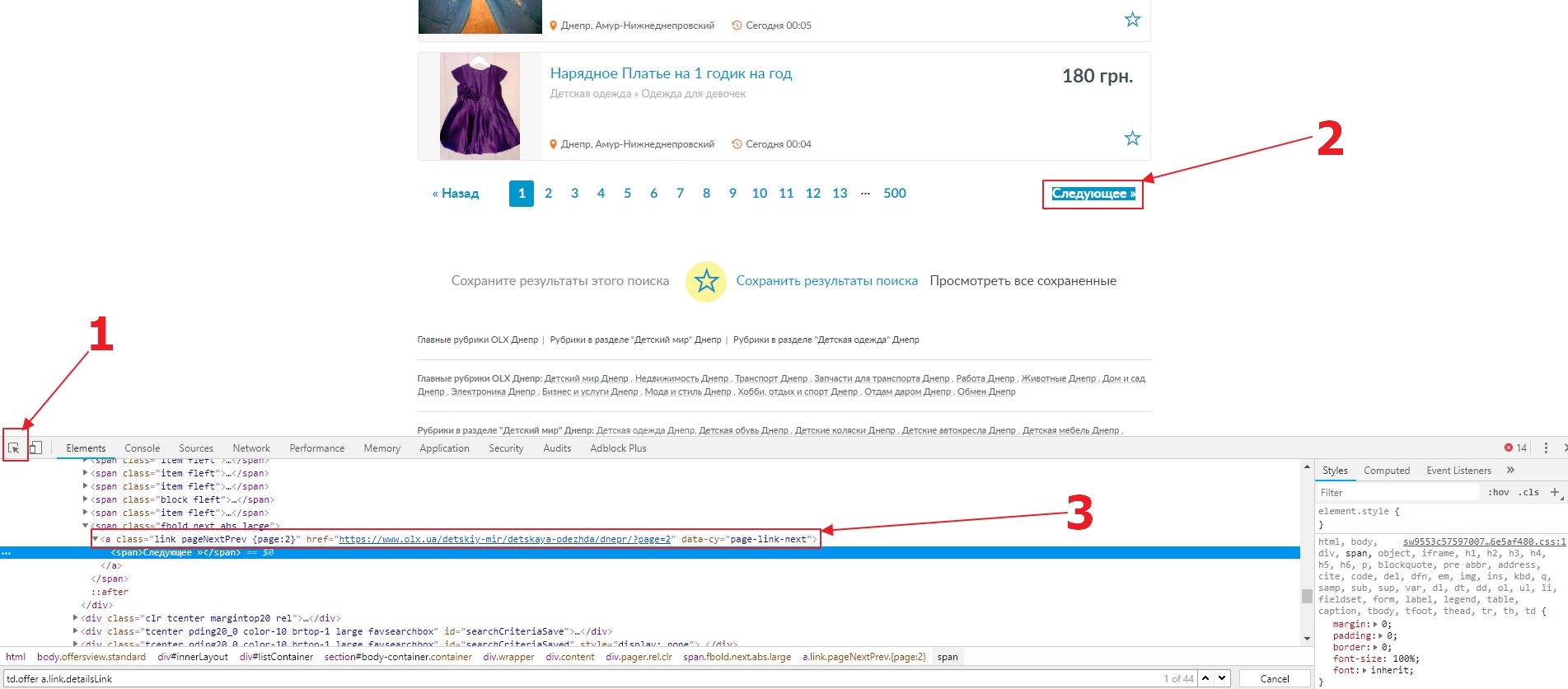
Перейдем к пагинатору. По аналогии с тем как мы находили блок с объявлением, найдем в пагинаторе ссылку на следующую страницу (3). Таким образом мы получим селектор a[data-cy="page-link-next"]. Удостоверимся, что он один на странице.
{kind=link}
Теперь у нас есть все, чтобы описать логику работы парсера в каталоге. Для навигации по страницам каталога мы будем использовать пул ссылок. Это позволит нам использовать одну логику для всех страниц каталога. Поэтому наш парсер будет выглядеть вот так:
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Кладем в пул ссылок стартовый URL
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Начинаем итерировать по пулу и загружать каждую страницу
- walk:
to: links
do:
# Находим ссылку на следующую страницу
- find:
path: a[data-cy="page-link-next"]
do:
# Парсим ссылку
- parse:
attr: href
# Добавляем ее в пул
- link_add
# Находим ссылку на объявление
- find:
path: a.link.detailsLink
do:
# Парсим ссылку
- parse:
attr: href
# Пока больше ничего не делаем
Этот код пройдет по всем страницам каталога, зайдет в блоки с объявлениями и спарсит оттуда ссылку на страницу объявления.
Теперь нам надо описать логику сбора данных в датасет со страницы объявления. Для этого откроем любое объявление и точно также, как мы определяли селекторы для блоков в каталоге мы будем находить элементы с интересующей нас информацией и составлять для них CSS селекторы.
- Селектор для блока с объявлением на странице:
div#offer_active. Мы первоначально будем заходить в этот блок, чтобы в случае его отсутствия у нас не создавался бы пустой объект. - Название товара:
h1. Заметьте, что селекторы строятся относительно текущего блока (div#offer_active). - Адрес:
address>p - Номер объявления:
em > small(тут потребуется фильтрация при парсинге, чтобы убрать лишний текст) - Дата и время размещения объявления:
em(потребуется перед парсингом удалить ноды a и small, а также немного очистить данные) - У нас есть таблица с деталями, но поля там могут быть разные, в зависимости от типа объявлений. Поэтому, мы будем собирать названия полей и значения. Подробное пояснение будет в коде, а селектор на эту таблицу:
table.details - Описание:
div#textContent - Изображение:
div#photo-gallery-opener > img(так как нам нужно полноразмерное изображение, надо будет отрезать часть URL которая содержит размер изображения. Используем для этого фильтрацию.) - Цена:
div.price-label - Имя продавца:
div.offer-user__details > h4 - Телефон: телефона на странице нет, чтобы его забрать нам придется делать дополнительный запрос. Каким образом, мы рассмотрим чуть позже.
Давайте напишем часть парсера для забора всех данных со страницы объявления, кроме телефона (пока) и посмотрим что мы получим в датасете:
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Кладем в пул ссылок стартовый URL
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Начинаем итерировать по пулу и загружать каждую страницу
- walk:
to: links
do:
# Находим ссылку на следующую страницу
- find:
path: a[data-cy="page-link-next"]
do:
# Парсим ссылку
- parse:
attr: href
# Добавляем ее в пул
- link_add
# Находим ссылку на объявление
- find:
path: a.link.detailsLink
do:
# Парсим ссылку
- parse:
attr: href
# Переходим на страницу с объявлением
- walk:
to: value
do:
# Находим элемент контейнера в котором хранятся все данные объявления
- find:
path: 'div#offer_active'
do:
# Создаем объект данных с именем item (одна запись в датасете)
- object_new: item
# Находим элемент с заголовком объявления
- find:
path: h1
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: title
# Находим элемент с описанием
- find:
path: 'div#textContent'
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: description
# Находим элемент с номером объявления
- find:
path: 'em > small'
do:
# Парсим текст, используя фильтр. Так как номер объявления состоит только из цмфр, мы применим фильтр для извлечения только цифр.
- parse:
filter: (\d+)
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: ad_id
# Находим элемент с датой и временем размещения объявления
- find:
path: 'em'
do:
# Удаляем из текущего элемента ноды с лишней информацией
- node_remove: a,small
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Удаляем запятую в конце
- normalize:
routine: replace_substring
args:
\,$: ''
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: date
# Находим элемент с ценой
- find:
path: div.price-label
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: price
# Находим элемент с именем продавца
- find:
path: div.offer-user__details > h4
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: seller
# Находим элемент с адресом
- find:
path: address > p
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: address
# Находим элемент с изображением
- find:
path: div#photo-gallery-opener > img
do:
# Парсим аттрибут src и используем фильтр для отрезания конечной части с размером
- parse:
attr: src
filter: ^([^;]+)
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: image
# Также сохраним в датасете URL на страницу объявления
# для этого используем статическую переменную url
- static_get: url
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: url
# Распарсим таблицу с деталями
- find:
path: table.details
do:
# Находим все строки таблицы в котором есть ячейка с классом value
- find:
path: tr:haschild(td.value)
do:
# Заходим в ячейку th чтобы собрать имя поля
- find:
path: th
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в переменную fieldname
- variable_set: fieldname
# Заходим в ячейку td чтобы собрать данные поля
- find:
path: td
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле определенное переменной fieldname объекта item
- object_field_set:
object: item
field:
# Сохраняем объект item в датасет
- object_save:
name: item
# Выходим из выполнения кода для проверки корректности сбора данных
- exit
Как результат мы получим следующую запись в датасете:
[{
"item": {
"ad_id": "574946238",
"address": "Днепр, Днепропетровская область, Индустриальный",
"date": "в 22:06, 9 февраля 2019",
"description": "СОСТОЯНИЕ НОВОГО. Деффектов никаких нет. Без следов носки. Брендовый красивенный демисезонный комбинезон F&F (Англия) для мальчика 3-6 мес. Сезон весна, сразу как снимите зимний паркий комбинезон. Покупкой будете очень довольны- эта вещь Вас действительно порадует. Качество английское, а значит супер, приятная ткань, швы не торчат. Утеплитель и подкладка в идеале. Из новой коллекции, яркий принт. На малыше смотрится бомбезно. Удобный, легко одевается- продольная молния, НЕ кнопки. Моделька очень удачная, эргономичная, правильного покроя- чётко сидит по фигуре (не висит мешком). Внутри до середины утеплён флисом (подходит и на холодную весну). Перед продажей постиран- чистенький - можно сразу носить. В комплект входят варежки и фирменная деми шапочка Early Days в тон к комбезу (двойная вязка) - состояние новой, БЕЗ катышек. Глубокая, хорошо прикрывает ушки, не сползает. Продажа только комплектом. Замеры: длина от плеча до пяточки по спинке 61; от шеи до пяточки по спинке 62; от шеи до памперса по спинке 44; от верха капюшона до пяточки по спинке 81; ПОГ от подмышки до подмышки 34; рукав от плеча 23; рукав от шеи 29; ширина в плечах 28; шаговый от памперса до пяточки 21. Пересылаю. Смотрите все мои объявления Есть точно такой же комбинезон в размере 0-3 мес. (покупала ростовкой для сына и племяша). Смотрите в моих объявлениях На 3-6 мес. есть еще серебристый комбез чуть полегче. Есть комбинезоны на другой возраст. Есть пакеты фирменной одежды для мальчика 0-6 мес. Также продам курточки на старший возраст, жилетки Спрашивайте, не всё выставлено. Скину фото что есть. Можно писать и в Viber. Отвечаю сразу",
"image": "https://apollo-ireland.akamaized.net:443/v1/files/yxyp673xu3zj2-UA/image",
"price": "600 грн.",
"seller": "BRAND CLOTHING",
"title": "Комбинезон F&Fдемисезонный 3-6 мес. Весна next gap деми + шапка",
"url": "https://www.olx.ua/obyavlenie/kombinezon-f-fdemisezonnyy-3-6-mes-vesna-next-gap-demi-shapka-IDCUpMq.html#006bc65a76;promoted",
"Объявление от": "Частного лица",
"Размер": "68",
"Состояние": "Б/у",
"Тип одежды": "Одежда для мальчиков"
}
}]
Все прекрасно собралось, поэтому сейчас мы будем смотреть как нам забрать номер телефона. Для этого откроем страницу с объявлением, затем инструменты для разработчика, и перейдем во вкладку Network (1). Внутри этой вкладки отметим показывать только XHR запросы (2) и нажмем на очистку всех запросов (чтобы не путаться). После чего нажмем на кнопку «Показать телефон» (3). Мы увидим, что браузер сделал запрос к серверу (4).
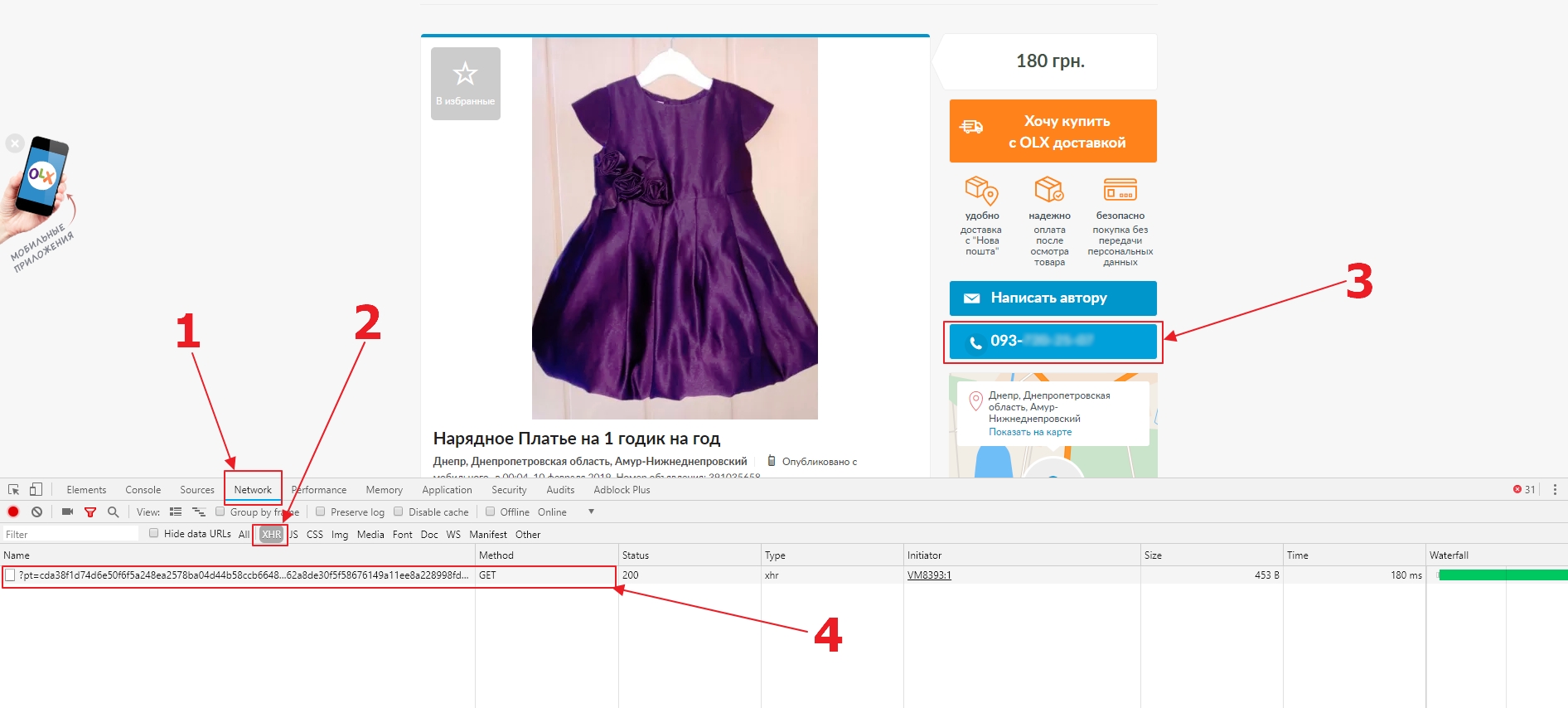{kind=link}
Теперь откроем запрос и увидим адрес (1) куда он посылается и какие данные (2) он отправляет.
{kind=link}
Теперь у нас есть URL: https://www.olx.ua/ajax/misc/contact/phone/qsKeK/
и параметр pt cda38f1d74d6e50f6f5a248ea2578ba04d44b58ccb6648718ce825a15dd1c036494b2cd1c6cb27762a8de30f5f58676149a11ee8a228998fd7f6b8cde5bb83a9
Очевидно, что для того, чтобы эмулировать такой запрос нам надо иметь ID объявления qsKeK и параметр pt. Если мы поищем их, то обнаружим, что параметр есть в JavaScript на странице, а значит мы можем извлечь его используя регулярное выражение. ID объявления можно вытащить из кнопки «Показать телефон». Это также даст нам возможность забирать телефоны только там, где они есть. Логика будет простой, мы будем заходить в элемент с кнопкой и делать определенные действия, а если кнопки не будет, то и действия не будут совершены. Изменим наш код и добавим фрагмент для забора телефонного номера.
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Кладем в пул ссылок стартовый URL
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Начинаем итерировать по пулу и загружать каждую страницу
- walk:
to: links
do:
# Находим ссылку на следующую страницу
- find:
path: a[data-cy="page-link-next"]
do:
# Парсим ссылку
- parse:
attr: href
# Добавляем ее в пул
- link_add
# Находим ссылку на объявление
- find:
path: a.link.detailsLink
do:
# Парсим ссылку
- parse:
attr: href
# Переходим на страницу с объявлением
- walk:
to: value
do:
# Находим элемент контейнера в котором хранятся все данные объявления
- find:
path: 'div#offer_active'
do:
# Создаем объект данных с именем item (одна запись в датасете)
- object_new: item
# Находим элемент с заголовком объявления
- find:
path: h1
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: title
# Находим элемент с описанием
- find:
path: 'div#textContent'
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: description
# Находим элемент с номером объявления
- find:
path: 'em > small'
do:
# Парсим текст, используя фильтр. Так как номер объявления состоит только из цмфр, мы применим фильтр для извлечения только цифр.
- parse:
filter: (\d+)
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: ad_id
# Находим элемент с датой и временем размещения объявления
- find:
path: 'em'
do:
# Удаляем из текущего элемента ноды с лишней информацией
- node_remove: a,small
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Удаляем запятую в конце
- normalize:
routine: replace_substring
args:
\,$: ''
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: date
# Находим элемент с ценой
- find:
path: div.price-label
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: price
# Находим элемент с именем продавца
- find:
path: div.offer-user__details > h4
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: seller
# Находим элемент с адресом
- find:
path: address > p
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: address
# Находим элемент с изображением
- find:
path: div#photo-gallery-opener > img
do:
# Парсим аттрибут src и используем фильтр для отрезания конечной части с размером
- parse:
attr: src
filter: ^([^;]+)
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: image
# Также сохраним в датасете URL на страницу объявления
# для этого используем статическую переменную url
- static_get: url
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: url
# Распарсим таблицу с деталями
- find:
path: table.details
do:
# Находим все строки таблицы в котором есть ячейка с классом value
- find:
path: tr:haschild(td.value)
do:
# Заходим в ячейку th чтобы собрать имя поля
- find:
path: th
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в переменную fieldname
- variable_set: fieldname
# Заходим в ячейку td чтобы собрать данные поля
- find:
path: td
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле определенное переменной fieldname объекта item
- object_field_set:
object: item
field:
# Находим элемент script с токеном для запроса телефона (ищем во всем документе, потому что мы сейчас находимся в блоке где нет этого JavaScript)
- find:
in: doc
path: script:contains("phoneToken")
do:
# Парсим только токен, используя регулярное выражение
- parse:
filter: \'([^']+)\'
# Сохраняем значение в переменную
- variable_set: token
# Находим элемент с кнопкой Показать телефон
- find:
path: li.link-phone
do:
# Парсим ID объявления
- parse:
attr: class
filter: \'id\'\:\'([^']+)\'
# Сохраняем значение в переменную
- variable_set: id
# Делаем паузу от 5 до 10 секунд
- sleep: 5:10
# Делаем запрос на сервер
- walk:
to: https://www.olx.ua/uk/ajax/misc/contact/phone//?pt=
headers:
accept: '*/*'
accept-language: ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7
x-requested-with: XMLHttpRequest
do:
# Выходим из выполнения кода для проверки корректности запроса
- exit
# Сохраняем объект item в датасет
- object_save:
name: item
# Выходим из выполнения кода для проверки корректности сбора данных
- exit
Если мы запустим парсер в режиме отладки, в логе мы увидим, что сервер отправляет нам следующую структуру:
067-XXX-XX-XX
То есть для того, чтобы спарсить номер, нам надо использовать селектор body_safe > value. Допишем наш парсер:
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Кладем в пул ссылок стартовый URL
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Начинаем итерировать по пулу и загружать каждую страницу
- walk:
to: links
do:
# Находим ссылку на следующую страницу
- find:
path: a[data-cy="page-link-next"]
do:
# Парсим ссылку
- parse:
attr: href
# Добавляем ее в пул
- link_add
# Находим ссылку на объявление
- find:
path: a.link.detailsLink
do:
# Парсим ссылку
- parse:
attr: href
- variable_set:
field: repeat
value: "yes"
# Переходим на страницу с объявлением с режимом повторного забора если что-то пойдет не так
- walk:
to: value
repeat:
do:
- variable_clear: ok
# Находим элемент контейнера в котором хранятся все данные объявления
- find:
path: 'div#offer_active'
do:
- variable_set:
field: ok
value: 1
# Создаем объект данных с именем item (одна запись в датасете)
- object_new: item
# Находим элемент с заголовком объявления
- find:
path: h1
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: title
# Находим элемент с описанием
- find:
path: 'div#textContent'
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: description
# Находим элемент с номером объявления
- find:
path: 'em > small'
do:
# Парсим текст, используя фильтр. Так как номер объявления состоит только из цмфр, мы применим фильтр для извлечения только цифр.
- parse:
filter: (\d+)
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: ad_id
# Находим элемент с датой и временем размещения объявления
- find:
path: 'em'
do:
# Удаляем из текущего элемента ноды с лишней информацией
- node_remove: a,small
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Удаляем запятую в конце
- normalize:
routine: replace_substring
args:
\,$: ''
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: date
# Находим элемент с ценой
- find:
path: div.price-label
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: price
# Находим элемент с именем продавца
- find:
path: div.offer-user__details > h4
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: seller
# Находим элемент с адресом
- find:
path: address > p
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: address
# Находим элемент с изображением
- find:
path: div#photo-gallery-opener > img
do:
# Парсим аттрибут src и используем фильтр для отрезания конечной части с размером
- parse:
attr: src
filter: ^([^;]+)
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: image
# Также сохраним в датасете URL на страницу объявления
# для этого используем статическую переменную url
- static_get: url
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: url
# Распарсим таблицу с деталями
- find:
path: table.details
do:
# Находим все строки таблицы в котором есть ячейка с классом value
- find:
path: tr:haschild(td.value)
do:
# Заходим в ячейку th чтобы собрать имя поля
- find:
path: th
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в переменную fieldname
- variable_set: fieldname
# Заходим в ячейку td чтобы собрать данные поля
- find:
path: td
do:
# Парсим текст из элемента
- parse
# Нормализуем данные (пробельные символы в пробелы), удаляем дубликаты пробелов и лидирующие и финиширующие пробелы
- space_dedupe
- trim
# Записываем данные в поле определенное переменной fieldname объекта item
- object_field_set:
object: item
field:
# Находим элемент script с токеном для запроса телефона (ищем во всем документе, потому что мы сейчас находимся в блоке где нет этого JavaScript)
- find:
in: doc
path: script:contains("phoneToken")
do:
# Парсим только токен, используя регулярное выражение
- parse:
filter: \'([^']+)\'
# Сохраняем значение в переменную
- variable_set: token
# Находим элемент с кнопкой Показать телефон
- find:
path: li.link-phone
do:
# Парсим ID объявления
- parse:
attr: class
filter: \'id\'\:\'([^']+)\'
# Сохраняем значение в переменную
- variable_set: id
# Делаем паузу от 5 до 10 секунд
- sleep: 5:10
# Делаем запрос на сервер
- walk:
to: https://www.olx.ua/uk/ajax/misc/contact/phone//?pt=
headers:
accept: '*/*'
accept-language: ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7
x-requested-with: XMLHttpRequest
do:
# Находим элемент с телефоном
- find:
path: body_safe > value
do:
# Парсим текст
- parse
# Записываем данные в поле объекта item
- object_field_set:
object: item
field: phone
# Сохраняем объект item в датасет
- object_save:
name: item
- cookie_reset
- find:
path: body
do:
- variable_get: ok
- if:
match: 1
do:
- variable_clear: repeat
else:
- error: Proxy is banned or page layout has been changed
- cookie_reset
- proxy_switch
- cookie_reset
Парсер работает на сайте OLX Украина и собирает все данные, которые нам нужны. Но он также может работать и на других сайтах. Например для того, чтобы он работал на сайте OLX Казахстан, нужно:
1. Изменить стартовый URL в строке 8: https://www.olx.kz/kk/moda-i-stil/odezhda/
2. Изменить URL в строке 210 (для забора телефонного номера): https://www.olx.kz/kk/ajax/misc/contact/phone//?pt=