
eBay – очень известная и популярная торговая площадка. Очень часто она используется небольшими продавцами для продажи товаров, также как и Amazon. Поэтому, данные с нее можно использовать для оценки торговой ниши при выходе на рынок с новым товаром.
Сайт eBay достаточно простой, не использует для показа страниц Javascript, и технических проблем для его парсинга быть не должно. Однако надо знать, что на выдачу данных по запросу на Ebay есть лимит. Поэтому, если вы хотите собрать все результаты, вам придется строить запросы таким образом, чтобы поисковый запрос или фильтрация возвращала такое количество объявлений, которое бы не превышало лимит.
Допустим, мы хотим продавать электронные книги. Попробуем найти нужную нам категорию и настроить фильтры. В Ebay есть категория Tablets & eReaders. Именно она нам и нужна как отправная точка. Откроем эту страницу в Google Chrome.
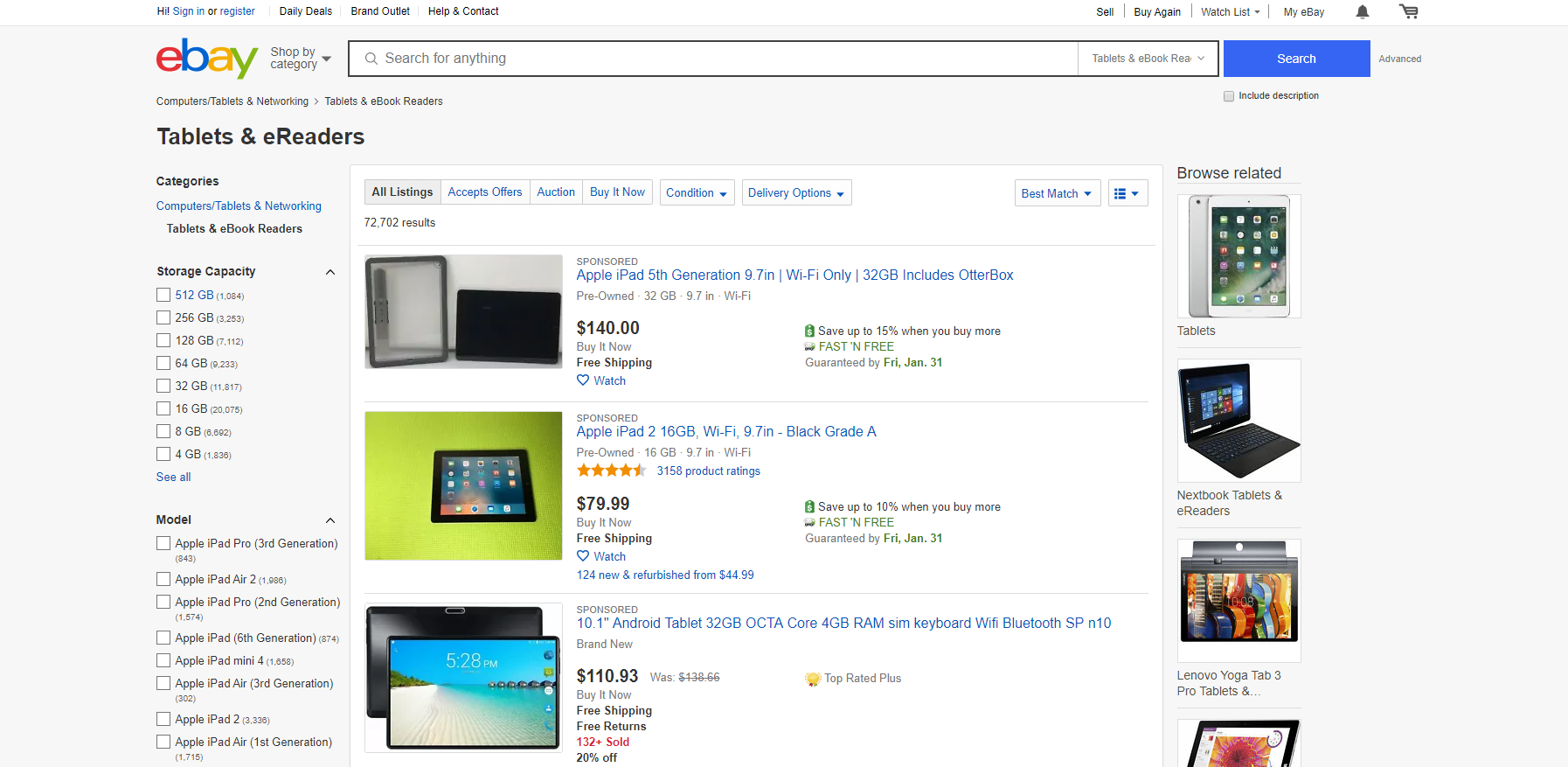
Однако в этой категории показываются также планшеты, а нас интересуют только электронные книги. Для этого нам надо настроить фильтр на тип товара. К сожалению, в основном наборе данного фильтра нет, поэтому на надо нажать на кнопку “More Filters”, что откроет окно со списком всех фильтров.
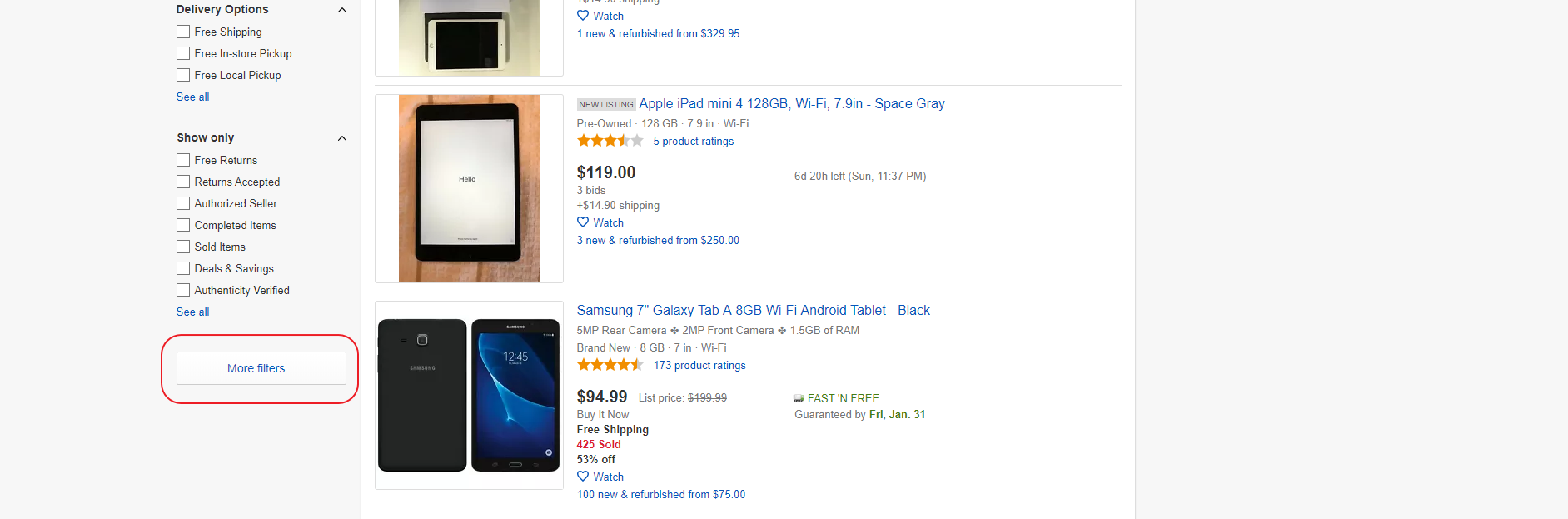
Там нам нужно найти фильтр “Type”, выбрать в нем опцию “eBook Reader” и нажать на кнопку “Apply”.
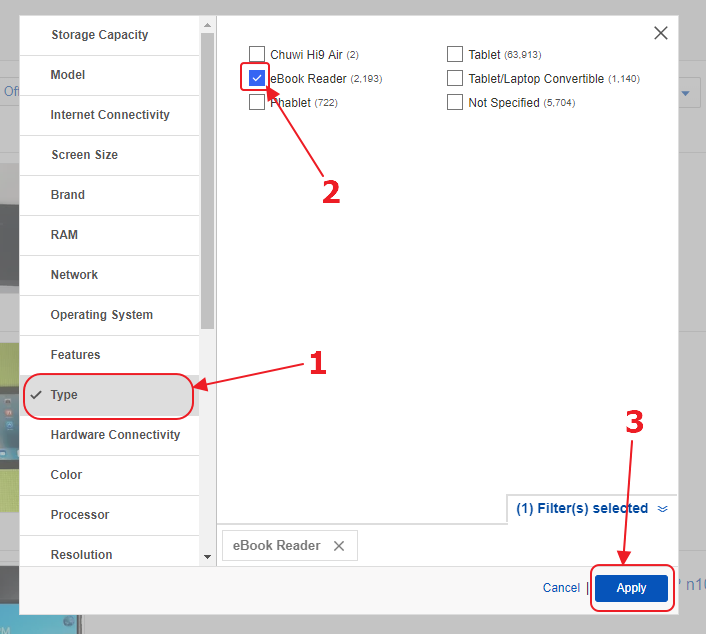
Мы видим, что товаров стало значительно меньше, однако нас интересуют только новые устройства. Поэтому нам нужно выбрать в фильтре “Condition” опцию “New”.
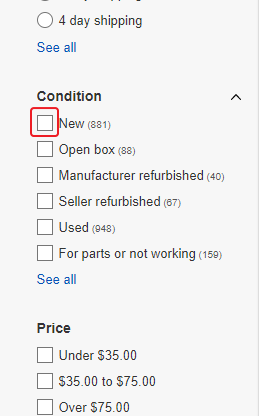
Также нас не интересуют аукционы, поэтому над блоком с листингами выберем опцию “Buy It Now”.
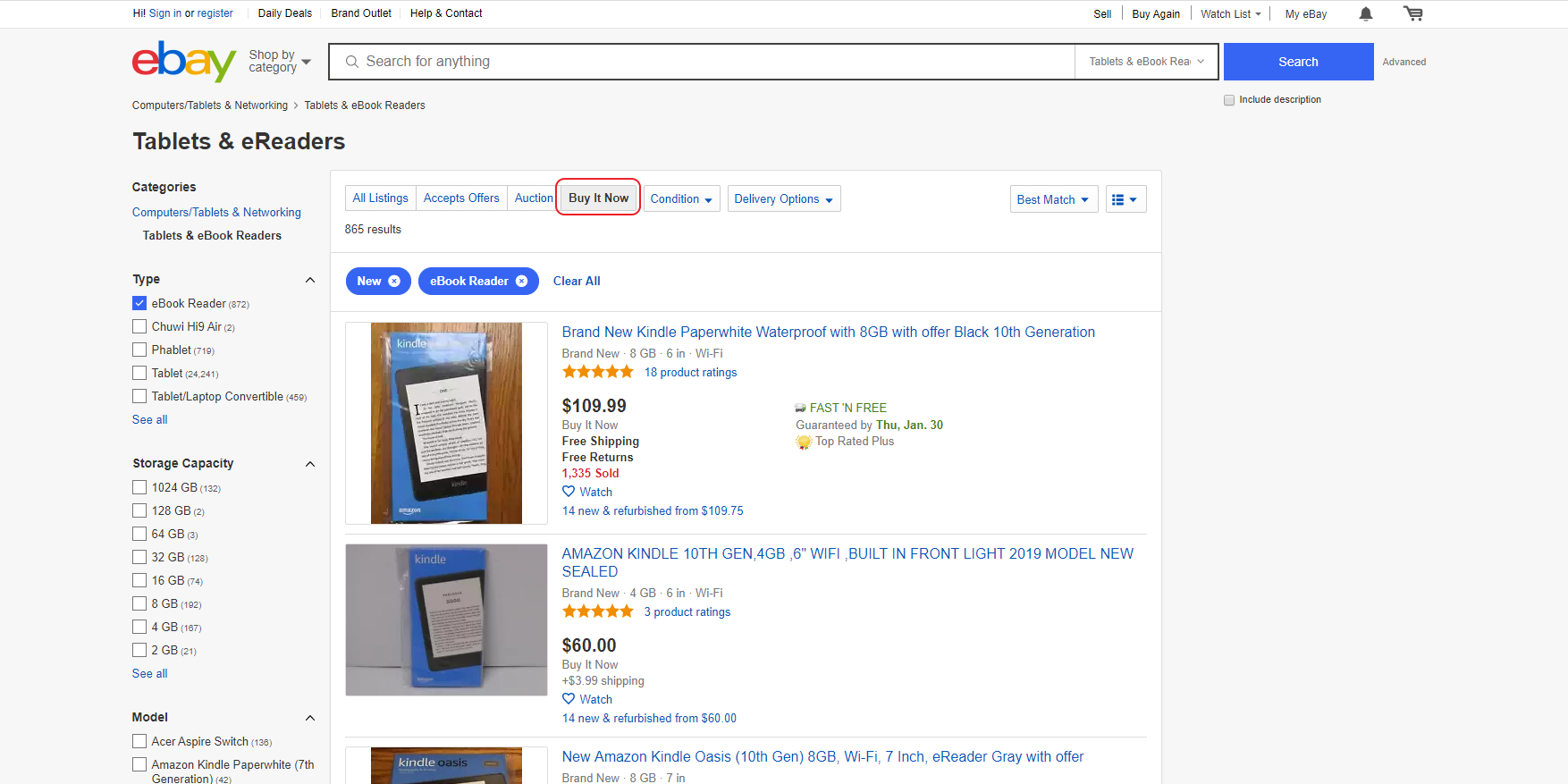
Теперь для экономии на запросах к серверу, увеличим количество выводимых результатов на странице. По умолчанию, eBay выводит 50 листингов. Мы можем выбрать 200, что сэкономит наши затраты на прохождение всего каталога отфильтрованной категории в 4 раза. Для этого под блоком с результатами надо выбрать количество выводимых результатов: 200.
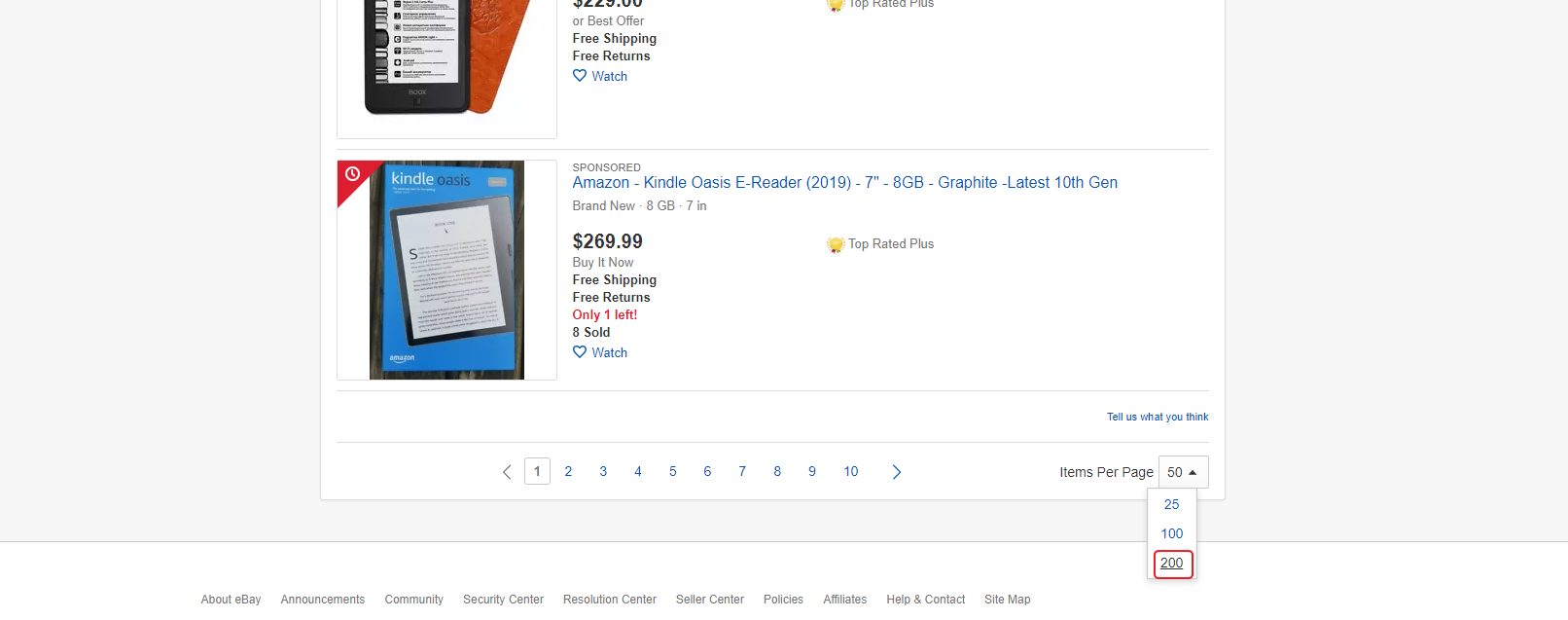
После того, как мы установили все фильтры и опции, нужно скопировать URL из адресной строки:
https://www.ebay.com/sch/Tablets-eBook-Readers/171485/i.html?_dcat=171485&_fsrp=1&_sacat=171485&rt=nc&Type=eBook%2520Reader&LH_ItemCondition=1000&LH_BIN=1&_ipg=200
Это и будет наш стартовый URL.
Далее нам надо отключить JS на странице. Делать мы это будем как обычно, при помощи расширения для Google Chrome: Quick Javascript Switcher. Далее откроем инструменты разработчика в Google Chrome, нажав клавиши Ctrl + Shift + I. После чего, используя инструмент для выбора элементов, найдем нужные нам блоки на странице и CSS селекторы для них. Во-первых, нас интересует блок с листингом, а во-вторых – ссылка на следующую страницу.
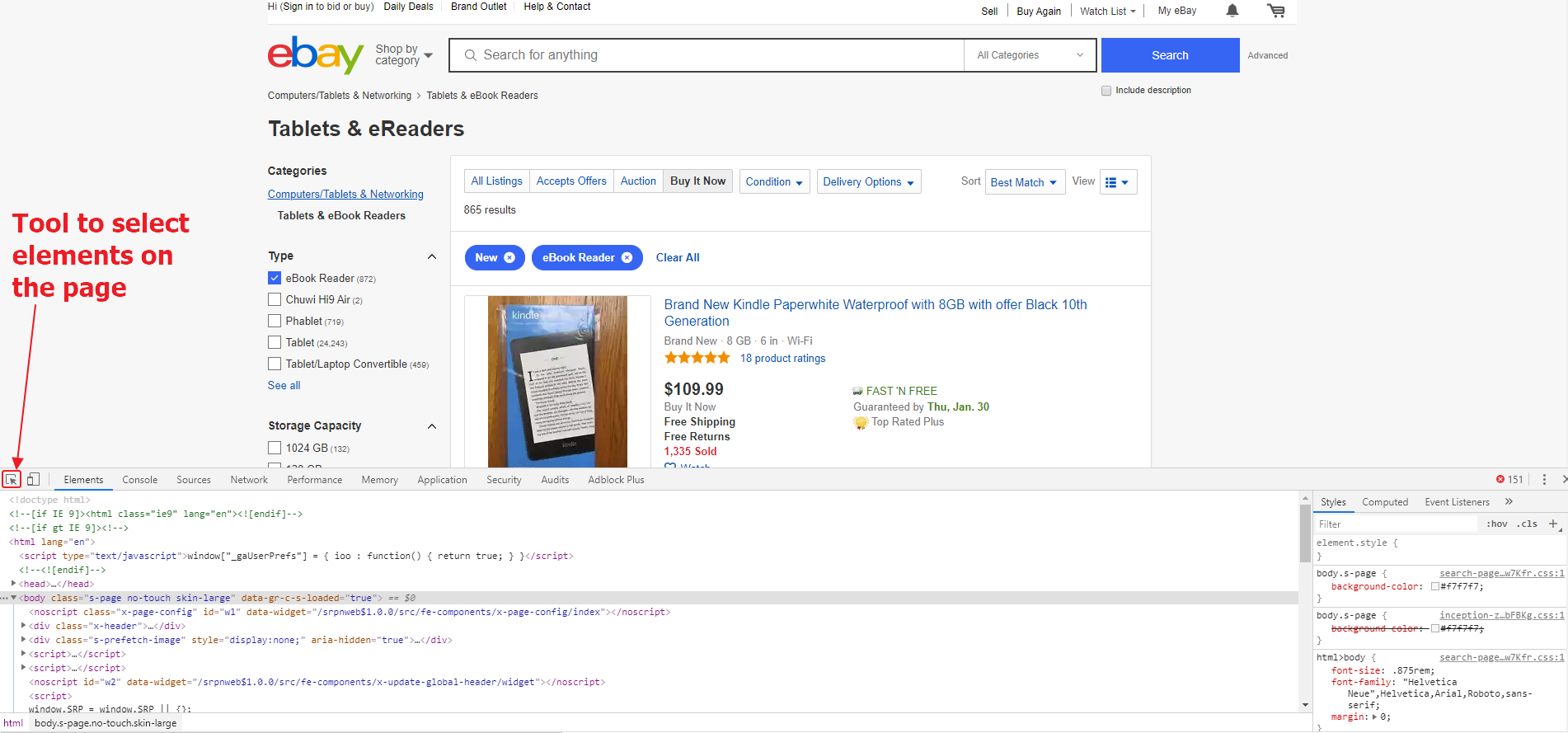
Сначала соберем все блоки с листингами, то есть определим CSS селектор для них.
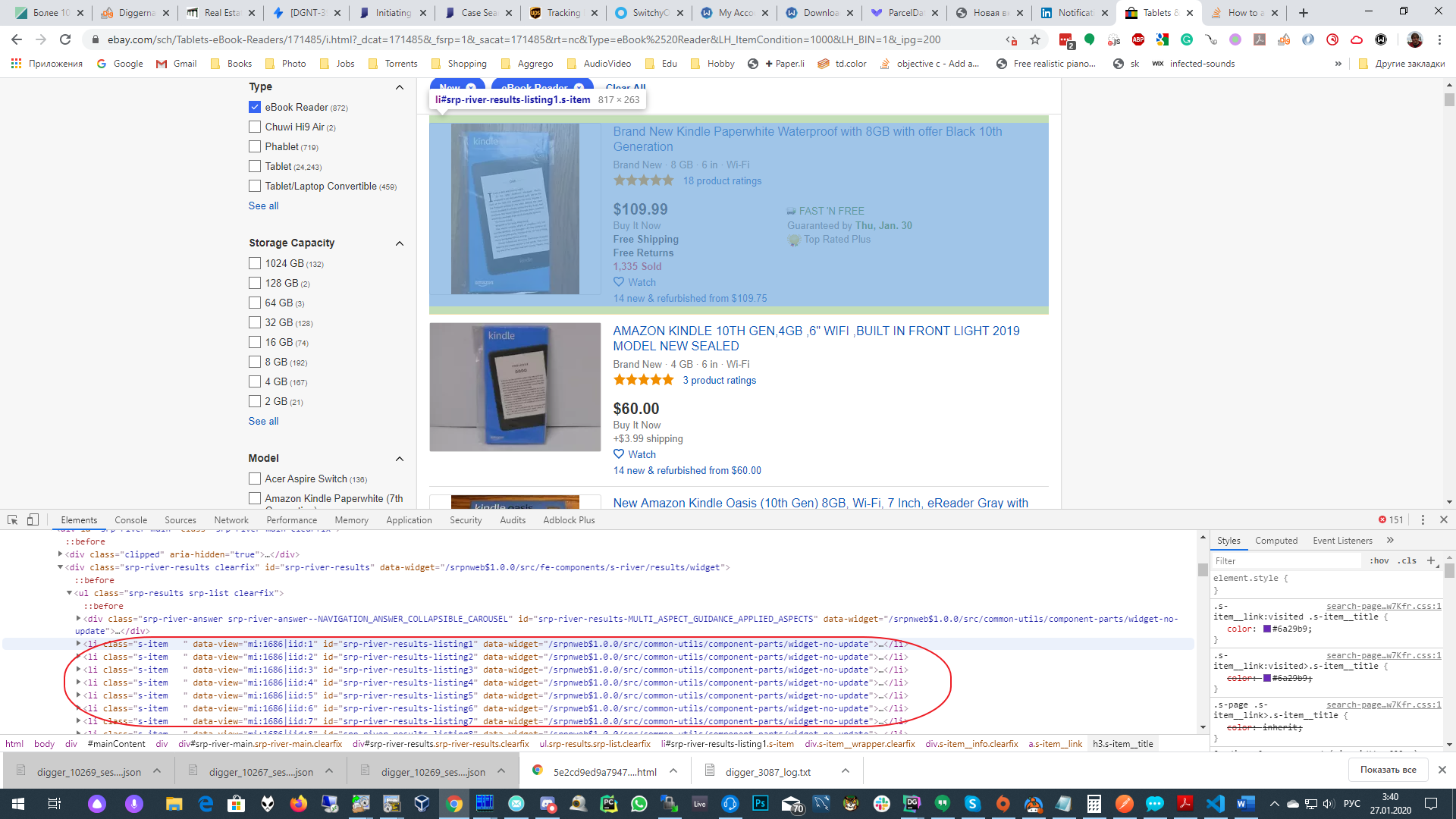
CSS селектор: ul > li.s-item. Для проверки сделаем поиск в секции “Elements” (нажав в ней Ctrl +F). И удостоверимся, что селектор выбирает все листинги. Мы увидим, что выбралось более 200 элементов, хотя должно быть 200 ровно. Это произошло, потому что Ebay, кроме найденных листингов, также показывает нам рекламные (Sponsored).
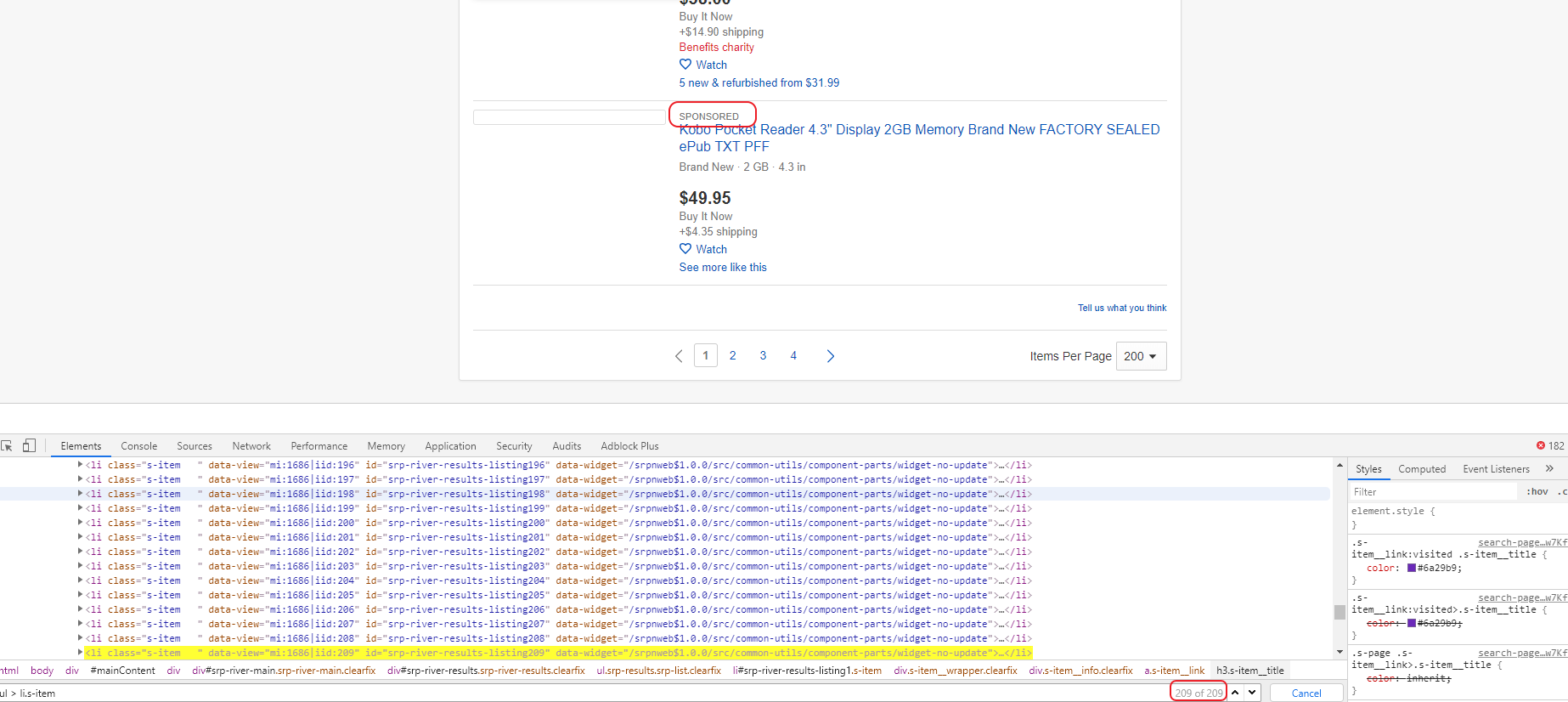
Отфильтровать их будет непросто, но мы попробуем это сделать. Нажмем на одну из букв в слове “SPONSORED” и посмотрим какой элемент откроется в окне “Elements”. Мы увидим набор элементов span, содержащих случайный набор символов.
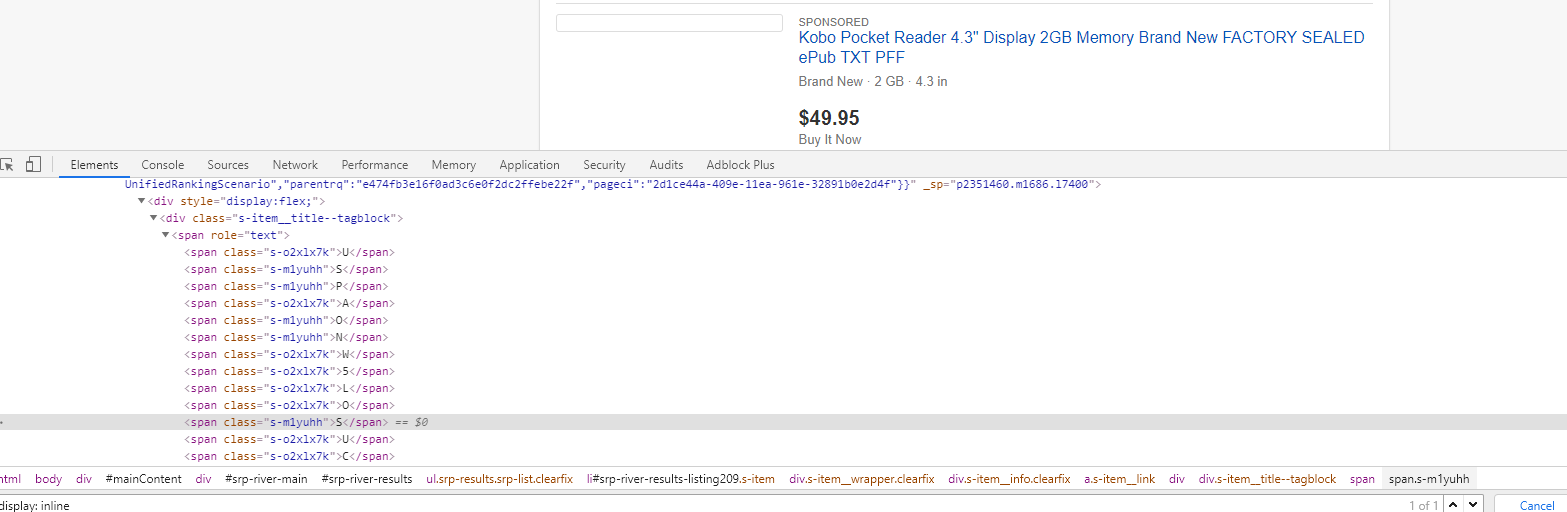
Мы видим, что у этих элементов разные классы. Вполне понятно, что “SPONSORED” на странице показывается за счет того, что один из классов показывается, а второй нет. Но мы не можем просто взять нужный нам класс как константу. Потому что, судя по имени класса, он не статичный, а генерируется. Поэтому на его имя мы не можем полагаться. Однако, если один из классов показывается, а второй нет, где-то на странице должен быть CSS который устанавливает это правило. Чтобы его найти, сделаем поиск в элементах по имени класса и обнаружим, что на странице присутствует следующий код:
Наша задача теперь, сконструировать для него селектор и проверить его в окне “Elements”, удостоверившись, что селектор выберет только 1 элемент на странице.
style:contains(“display: inline;”) – такой селектор будет прекрасно работать для нашей задачи.
Теперь, когда мы нашли нужный элемент, нам нужно вытащить оттуда класс, который показывается. Для этого в команде parse мы будем использовать опцию filter. Давайте посмотрим какое регулярное выражение поможет выделить имя нужного нам класса:
span\.([^\s\{]+)\s*\{\s*display\:\s*inline;
Используя это регулярное выражение , мы извлечем имя класса: s-m1yuhh.
Теперь, когда у нас есть класс, мы можем зайти в элемент span[role=”text”] и удалить все элементы span с классом отличным от нашего класса (который мы предварительно запишем в переменную class). Сделать это можно с помощью команды node_remove:
- node_remove: span:not(.<%class%>)
После чего нужно использовать команду parse и сравнить результат в регистре со строкой “SPONSORED”, используя команду if.
Таким образом мы сможем отсеять коммерческие листинги.
Теперь можно посмотреть в блок листинга и выбрать поля, которые мы будем собирать:
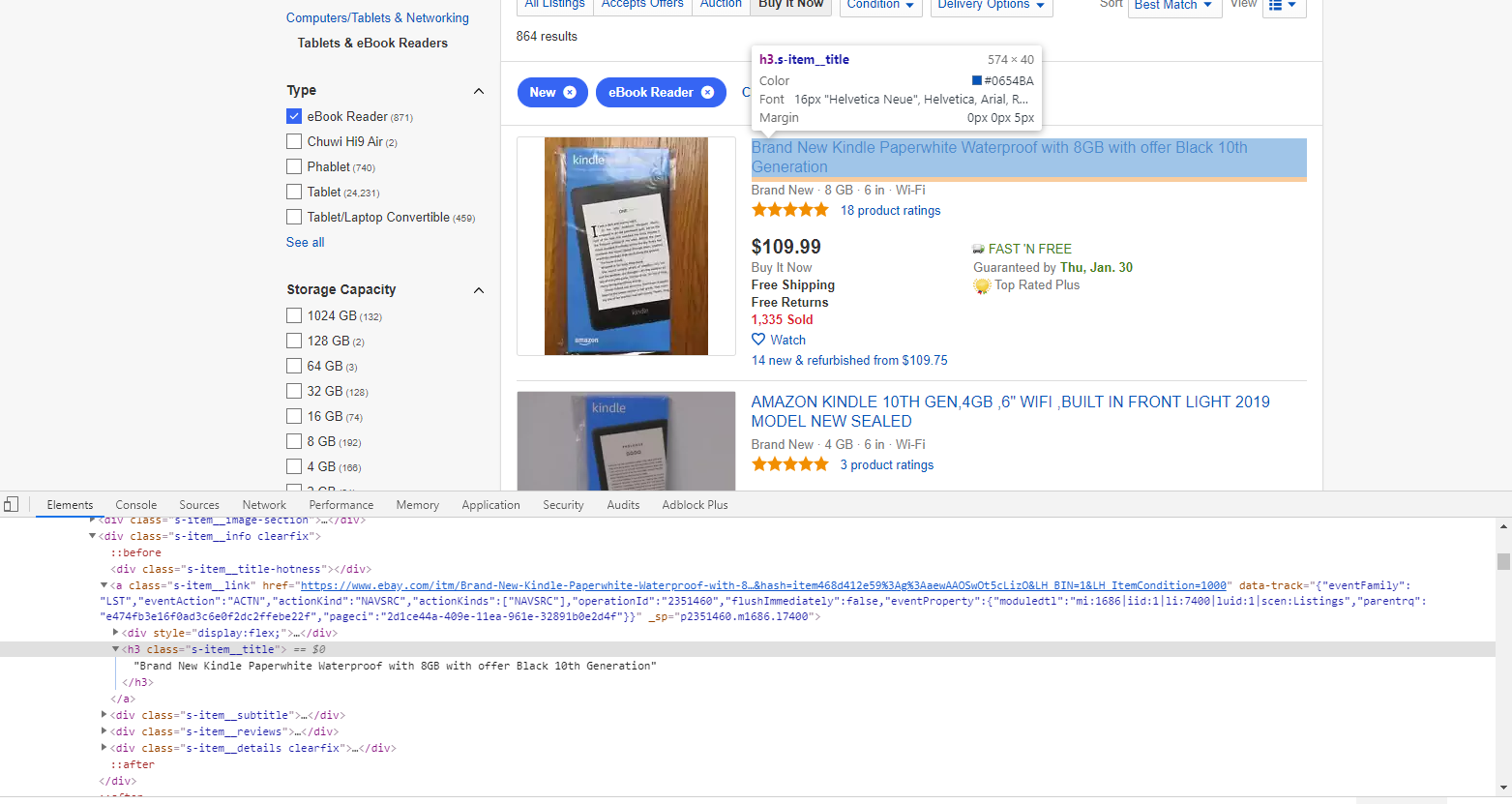
С этой страницы мы соберем:
- название товара:
h3.s-item__title - цену товара:
span.s-item__price - стоимость доставки:
span.s-item__shipping.s-item__logisticsCost - рейтинг листинга:
div.b-starrating > span.clipped - количество отзывов:
span.s-item__reviews-count > span:not(.clipped) - количество людей, отслеживающих этот листинг:
span.s-item__hotness:contains(“Watching”) - количество проданных товаров:
span.s-item__hotness:contains(“Sold”) - ссылка на товар:
a.s-item__link
В рамках этот статьи мы ограничимся сбором данных со страницы каталога, не заходя на страницу с товаром. Вы можете самостоятельно улучшить парсер eBay, добавив логику парсинга страницы товара. Для этого вы должны использовать команду walk для перехода на страницу с товаром и команды find для перехода по блокам, используя CSS селекторы.
Теперь, когда мы разобрали на составные части блок с данными о товаре и получили селекторы, давайте найдем селектор для перехода на следующую страницу каталога.
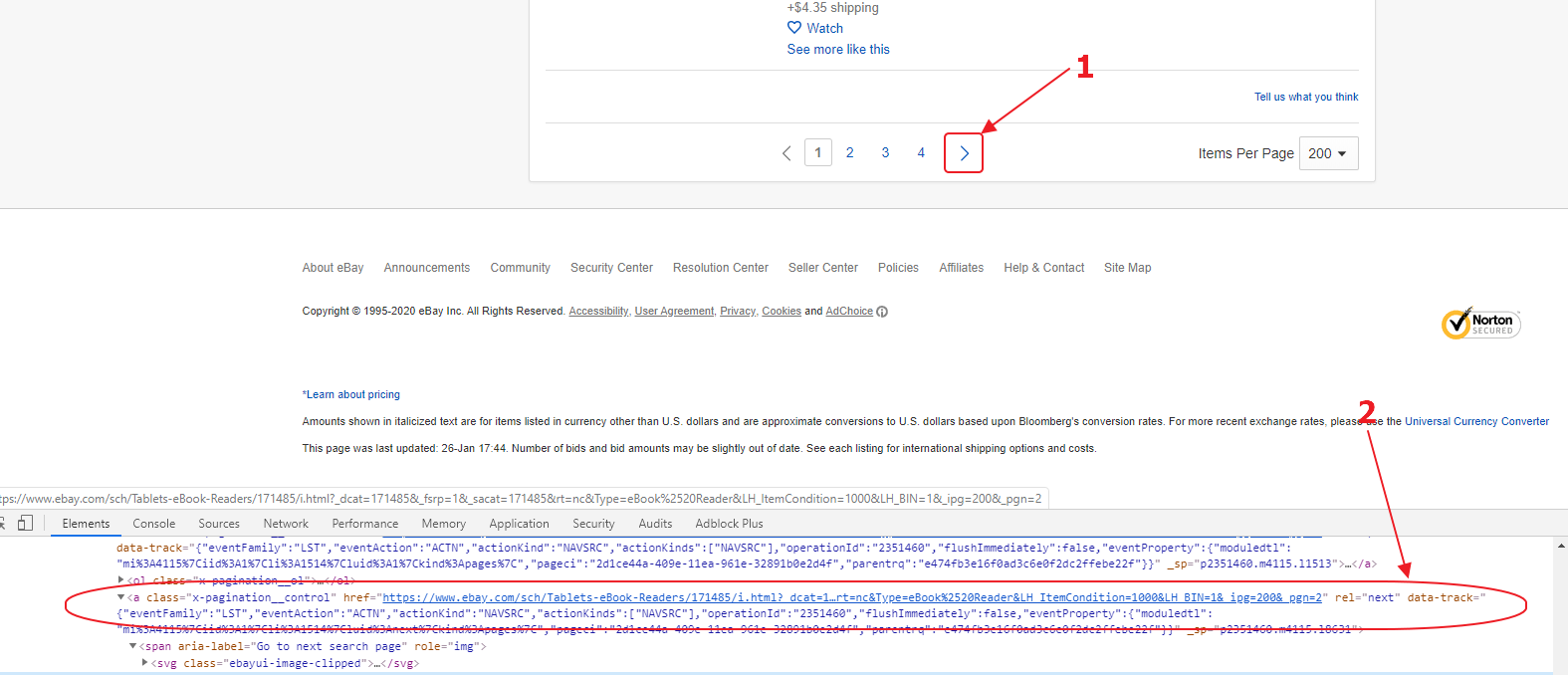
На изображении видно, что нам подойдет селектор a[rel=»next»]. Он один на странице, и все что нам остается сделать – отпарсить аттрибут href и положить значение в пул линков.
Мы готовы писать конфигурацию диггера:
---
config:
debug: 2
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
do:
# Добавляем стартовый URL в пул линков
- link_add:
url:
- https://www.ebay.com/sch/Tablets-eBook-Readers/171485/i.html?_dcat=171485&_fsrp=1&_sacat=171485&rt=nc&Type=eBook%2520Reader&LH_ItemCondition=1000&LH_BIN=1&_ipg=200
# Начинаем итерировать по пулу линков и заходим на страницы в пуле
- walk:
to: links
do:
# Очищаем переменные
- variable_clear: class
# Находим ссылку на следующую страницу
- find:
path: a[rel="next"]
do:
# Парсим значение в аттрибуте href
- parse:
attr: href
# Делаем стандартную очистку данных в регистре
- space_dedupe
- trim
# Проверяем, если ли какое-либо значение в регистре
- if:
match: \w+
do:
# Добавляем значение регистра в пул линков
- link_add
# Находим блок с CSS для извлечения класса отметки SPONSORED
- find:
path: 'style:contains("display: inline;")'
do:
# Парсим имя класса и записываем его в переменную
- parse:
filter: 'span\.([^\s\{]+)\s*\{\s*display\:\s*inline;'
- variable_set: class
# Находим блоки с листингами
- find:
path: ul > li.s-item
do:
# Очищаем переменные
- variable_clear: sponsored
# Определяем, листинг SPONSORED или нет
- find:
path: span[role="text"]
do:
- node_remove: span:not(.<%class%>)
- parse
- space_dedupe
- trim
- if:
match: SPONSORED
do:
- variable_set:
field: sponsored
value: 1
# Если листинг SPONSORED - игнорируем его
- variable_get: sponsored
- if:
match: 1
else:
# Это обычный листинг, собираем данные
# Создаем объект для хранения данных
- object_new: item
# Собираем название товара
- find:
path: h3.s-item__title
do:
- parse
- space_dedupe
- trim
- object_field_set:
object: item
field: name
# Собираем цену товара
- find:
path: span.s-item__price
do:
# Парсим только цифры, включаем регулярное выражение для случаев когда указано 2 цены
- parse:
filter:
- \$([0-9\.]+)\s+to
- \$([0-9\.]+)
# Проверяем есть ли в регистре цифры
- if:
match: \d+
do:
# Сохраняем значение в поле price как float
- object_field_set:
object: item
field: price
type: float
# Собираем стоимость доставки
- find:
path: span.s-item__shipping.s-item__logisticsCost
do:
# Проверяем бесплатная доставка или нет
- parse
- if:
match: Free
do:
- register_set: 0.0
- object_field_set:
object: item
field: delivery
type: float
else:
# Парсим цену доставки
- parse:
filter:
- \$([0-9\.]+)
- if:
match: \d+
do:
- object_field_set:
object: item
field: delivery
type: float
# Собираем рейтинг товара
- find:
path: div.b-starrating > span.clipped
do:
# Парсим только цифры рейтинга
- parse:
filter: ([0-9\.]+)\s+out
- if:
match: \d+
do:
- object_field_set:
object: item
field: rating
type: float
# Собираем количество отзывов
- find:
path: div.b-starrating > span.clipped
do:
# Парсим только цифры
- parse:
filter: (\d+)
- if:
match: \d+
do:
- object_field_set:
object: item
field: reviews
type: int
# Собираем количество людей, отслеживающих листинг
- find:
path: span.s-item__hotness:contains("Watching")
do:
# Парсим только цифры
- parse:
filter: (\d+)
- if:
match: \d+
do:
- object_field_set:
object: item
field: watching
type: int
# Собираем количество проданных товаров
- find:
path: span.s-item__hotness:contains("Sold")
do:
# Парсим только цифры
- parse:
filter: (\d+)
- if:
match: \d+
do:
- object_field_set:
object: item
field: sold
type: int
# Ссылка на товар
- find:
path: a.s-item__link
do:
- parse:
attr: href
- space_dedupe
- trim
- if:
match: \w+
do:
- normalize:
routine: url
- object_field_set:
object: item
field: url
# Сохраняем объект
- object_save:
name: item
# Делаем паузу между заборами страниц
- sleep: 3
Спасибо, научились-)