
Статья обновлена 19 января 2020 в связи с изменениями структуры JS необходимой для извлечения query_hash в парсере по тэгам. Механика автоподгрузки на страницах сайтов осуществляется с помощью Javascript. Поэтому, для того, чтобы определить на какой URL нам нужно обращаться и какие параметры использовать, нам нужно либо досконально изучить JS код который работает на странице, либо, и что предпочтительней, изучить запросы, которые делает браузер при прокрутке страницы вниз. Изучить запросы мы можем с помощью Инструментов для разработчика, которые встроены во все современные браузеры. В нашей статье мы будем использовать Google Chrome, но вы можете использовать любой другой браузер, приняв во внимание, что инструменты разработчика могут выглядеть по разному в разных браузерах.
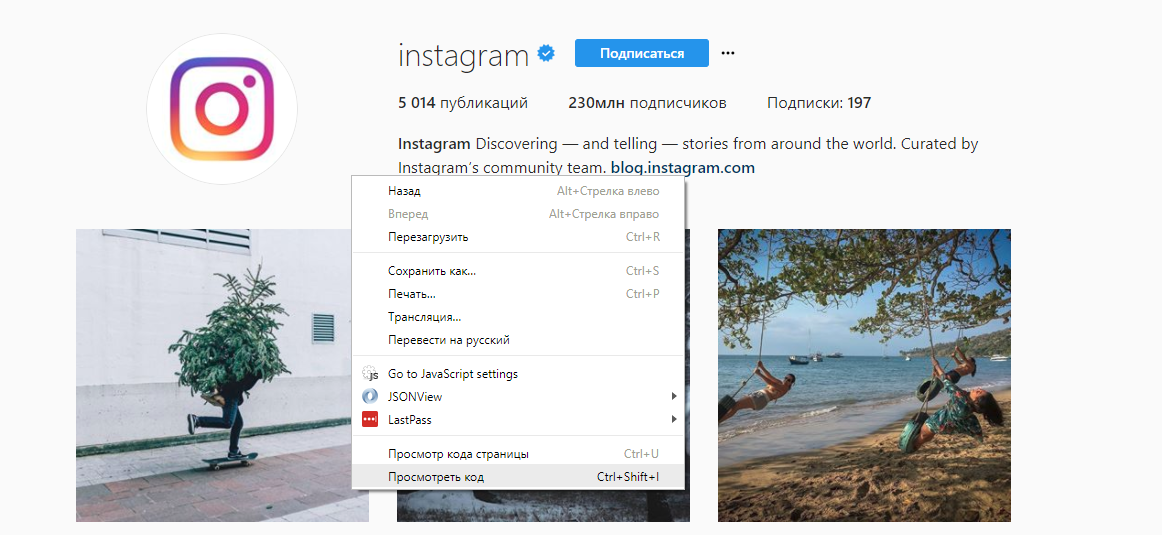
Изучать нашу задачу мы будем на примере Instagram, а именно, используя официальный канал Instagram. Откроем эту страницу в браузере, и запустим Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Просмотреть код» или нажмите «Ctrl+Shift+I»:
У нас откроется окно инструментов, где мы перейдем во вкладку Network и в фильтрах выберем показ только XHR запросов. Мы это делаем для того, чтобы отфильтровать ненужные нам запросы. После этого перезагрузим страницу в браузере с помощью кнопки Reload в интерфейсе браузера или клавиши «F5» на клавиатуре.
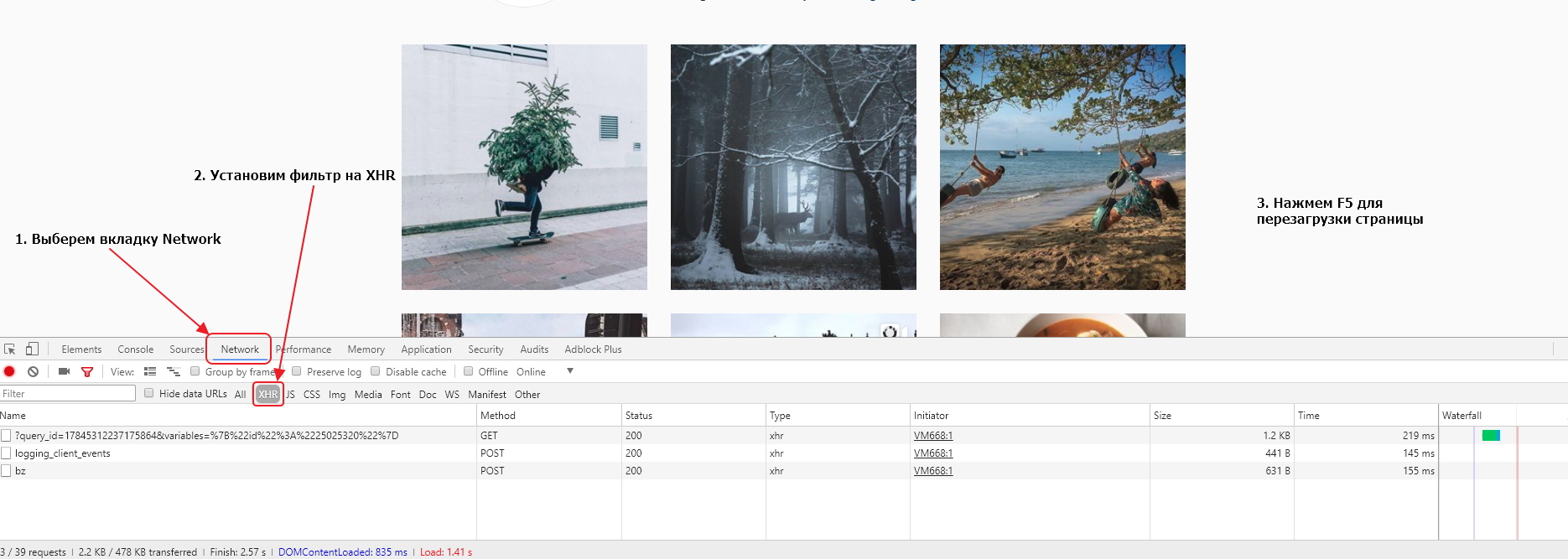
Давайте теперь прокрутим страницу вниз несколько раз с помощью колесика мышки, что вызовет подгрузку контента. Каждый раз, когда при прокручивании мы будем достигать нижней части страницы, JS будет делать XHR запрос на сервер, получать данные и добавлять их на страницу. В результате, у нас в списке окажется несколько запросов, которые выглядят почти одинаково. Скорее всего они нам и нужны.

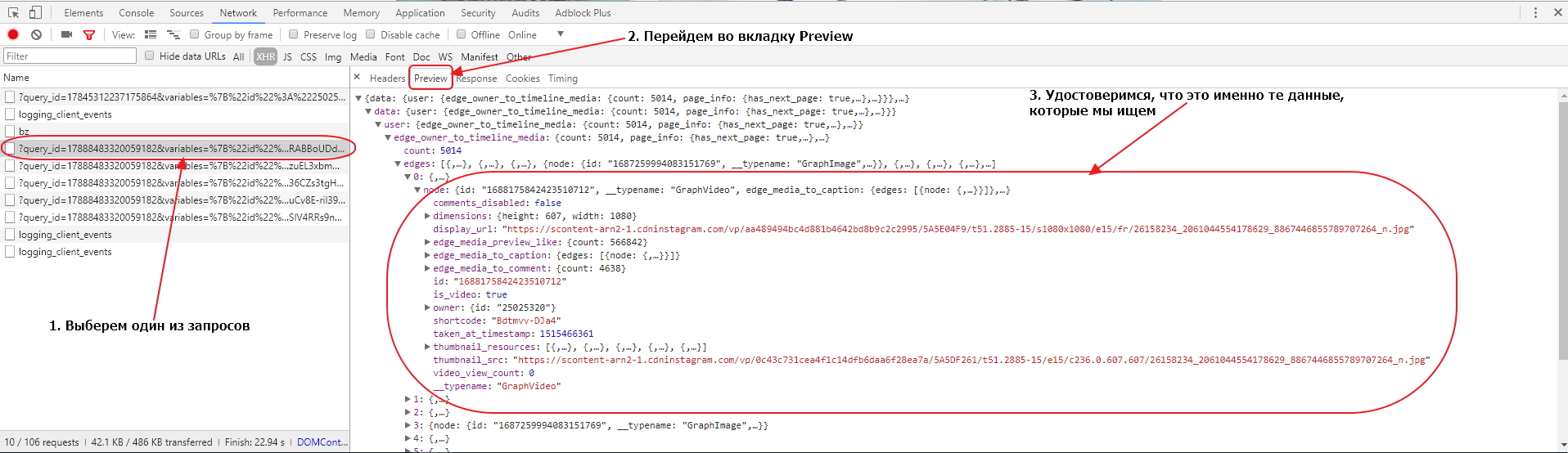
Чтобы удостовериться в этом, мы должны выбрать один из запросов и в открывшемся окне перейти во вкладку Preview. Там мы сможем увидеть отформатированное содержимое, которое сервер прислал в браузер по этому запросу. Доберемся до одного из конечных элементов и удостоверимся, что там находятся данные об изображениях, которые есть у нас на странице.
Убедившись, что это нужные нам запросы, рассмотрим один из них более внимательно. Для этого перейдем во вкладку Headers. Там мы можем найти информацию о том, на какой именно URL производится запрос, какой тип запроса (POST или GET) используется, а также какие параметры передаются с запросом.

Параметры запроса лучше изучать в секции Query String Parameters, прокрутив рабочее окно в панели инструментов вниз до конца:

Результатом нашего анализа станут следующие факты:
URL запроса: https://www.instagram.com/graphql/query/
Тип запроса: GET
Передаваемые параметры: query_hash и variables
Очевидно, что в query_hash передается статичный id, который генерируется, скорее всего, когда вы заходите на страницу. В variables же передаются некие параметры в JSON формате, влияющие на выборку данных.
Давайте проведем небольшой эксперимент, возьмем URL с параметрами, который использовался для загрузки данных:
https://www.instagram.com/graphql/query/?query_hash=df16f80848b2de5a3ca9495d781f98df&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%2C%22after%22%3A%22AQDsbvCEthjsp_O_8UO9vPTHKy6Qea2H_RRxe7v46B2XKXhSYVTv8FLSDk0BxmXqLw_T1R9aB8DB51Kp2hp80mP51bKdG9Ahy4eKWT9h3QplzA%22%7D
Если бы до последнего апдейта API мы бы взяли и вставили его в адресную строку браузера и нажали Enter, то мы бы увидели как загрузится страница в JSON формате:
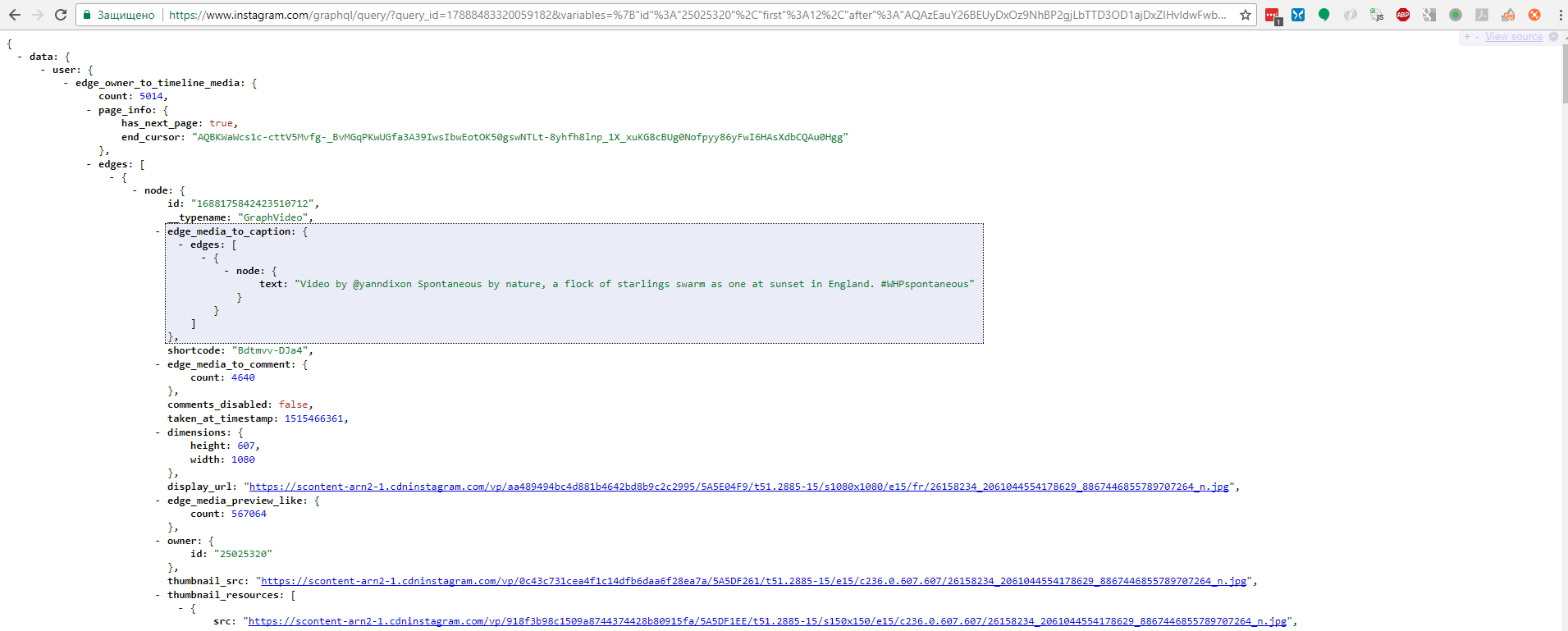
Однако, теперь просто так API Инстаграма не отдает данные, для этого необходимо рассчитать подпись для запроса и передать ее в заголовке запроса. Этот вопрос более подробно рассматривается ниже. Без корректного заголовка все что мы получим сейчас — это ошибку 403.
Теперь нам нужно понять, откуда берется query_hash. Если мы перейдем во вкладку Elements и попытаемся найти (CTRL+F) наш query_hash f2405b236d85e8296cf30347c9f08c2a, то мы узнаем что на самой странице его нет, а значит он подгружается или генерируется где-то в коде Javascript. Поэтому, перейдем опять во вкладку Network и поставим фильтр на JS. Таким образом мы увидим только запросы на JS файлы. Последовательно перебирая запрос за запросом, будем искать наш id в загруженных файлах: просто выбираем запрос, затем открываем в открывшейся панели вкладку Response чтобы увидеть содержимое JS и делаем поиск нашего id (CTRL+F). После нескольких неудачных попыток, мы обнаружим, что наш id находится в следующем JS файле:
https://www.instagram.com/static/bundles/ProfilePageContainer.js/031ac4860b53.js
а фрагмент кода, который обрамляет id, выглядит так:
s.pagination},queryId:"f2405b236d85e8296cf30347c9f08c2a"
Соответственно, для получения query_hash нам надо найти на первой странице URL на ProfilePageContainer.js файл, извлечь этот URL, забрать JS файл по этому URL, распарсить место с нужным нам id и записать его в переменную для дальнейшего использования.
Теперь давайте посмотрим, что за переменные передаются в variables:
{"id":"25025320","first":12,"after":"AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A"}
Если мы проанализируем все XHR запросы с догружаемыми данными, что мы обнаружим, что меняется только параметр after. Поэтому id скорее всего есть id канала, который мы парсим, first — количество записей, которые сервер должен отдать по запросу, а after — очевидно id последней показанной записи.
Нам нужно найти место, из которого мы можем извлечь id канала, для этого первым делом мы поищем текст 25025320 в исходном коде начальной страницы. Перейдем во вкладку Elements и сделаем поиск (CTRL+F) нашего id. Мы обнаружим, что он есть в JSON структуре на самой странице, именно оттуда мы и можем его извлечь:
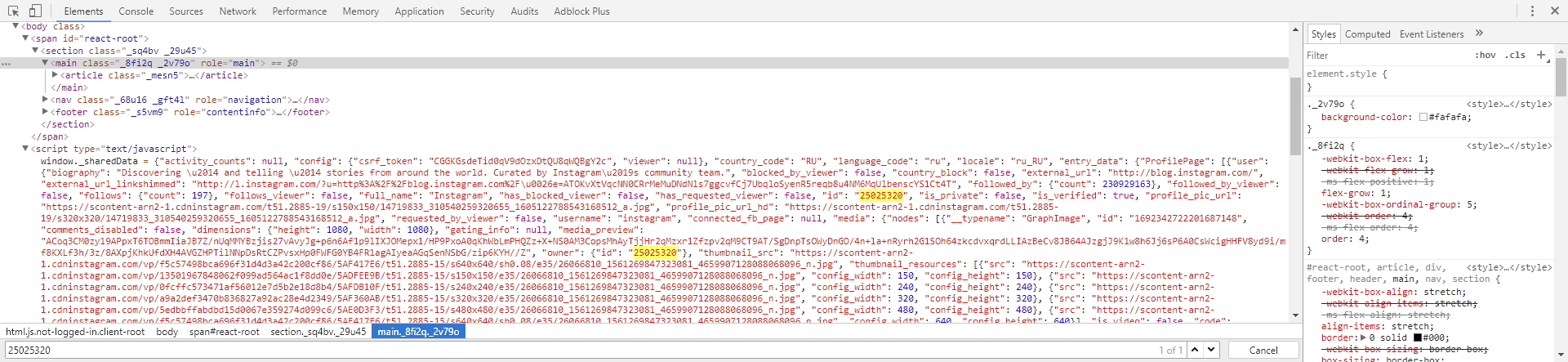
Вроде все понятно, но где нам брать этот самый after для каждой последующей подгрузки? Все очень просто. Если мы загрузим в браузере следующий URL:
https://www.instagram.com/graphql/query/?query_hash=df16f80848b2de5a3ca9495d781f98df&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%2C%22after%22%3A%22AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A%22%7D
мы увидим, что там есть следующая структура:
data: {
user: {
edge_owner_to_timeline_media: {
count: 5014,
page_info: {
has_next_page: true,
end_cursor: "AQCCoEpYvQtj0-NgbaQUg9g4ffOJf8drV2RieFJw1RA3E9lDoc8euxXjeuwlUEtXB6CRS9Zs2ZGJcNKseKF9f6b0cN0VC3ck8rnTfOw5q8nlJw"
}
}
}
}
То есть, в нашей логике мы сможем использовать значение поля has_next_page чтобы знать переходить ли на следующую страницу или нет и end_cursor как значение параметра after.
Сейчас мы напишем заготовку нашего парсера, загрузим первую страницу и попытаемся загрузить JS файл с query_id. Создайте диггер в вашем аккаунте Diggernaut и добавьте в него следующую конфигурацию:
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer\.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:Установите диггер в режим Отладка. Теперь нам нужно запустить наш парсер и после того как он отработает посмотреть лог. В конце лога мы увидим как диггернаут работает с JS файлами. Он преобразовывает их в следующую структуру:
А значит селектор для забора всего JS будет script. Давайте допишем функцию парсинга query_id из JS:
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer\.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Сохраняем полученное значение в переменной
- variable_set: queryidСохраним наш парсер и снова запустим. Подождем когда он закончит работу и посмотрим в лог. В логе мы увидим следующую строчку:
Set variable queryid to register value: 42323d64886122307be10013ad2dcc44
Это значит, что query_hash был успешно извлечен и записан в переменную с именем queryid.
Теперь мы извлечем id канала. Как вы помните, он есть в JSON объекте на самой странице. Поэтому нам нужно взять содержимое определенного элемента script, вытащить оттуда JSON, конвертировать его в XML и забрать нужное нам значение, используя CSS селектор.
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer\.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится id канала
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: chidЕсли вы внимательно посмотрите в лог, то увидите, что JSON структура трансформируется в DOM следующим образом:
qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz
US
1.5
480
360
profilePage_25025320
Discovering — and telling — stories from around the world. Curated by Instagram’s community
team.
false
false
http://blog.instagram.com/
http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M
230937095
false
197
false
Instagram
false
false
25025320
false
true
5014
GraphVideo
false
607
1080
https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg
573448
Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous
4709
1688175842423510712
true
25025320
Bdtmvv-DJa4
1515466361
150
150
https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
240
240
https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
320
320
https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
480
480
https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
640
640
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
2516274
...
AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ
true
45ca3dc3d5fd
true
Это поможет нам построить CSS селекторы для забора первых 12 записей и маркера последней записи, который нужен нам для забора следующих 12 записей. Напишем логику для извлечения данных, а также начем формировать пул (pool) линков со ссылками на фиды (feeds) с подгружаемыми данными. Далее начнем итерацию по пулу линков и посмотрим как преобразует Diggernaut полученный JSON, так, чтобы мы смогли построить корректные CSS селекторы для логики парсера.
Совсем недавно Instagram сделал изменения в публичном API, теперь для авторизация делается не по CSRF токену, а по специальной сигнатуре, которая рассчитывается используя новый параметр rhx_gis, передаваемый в sharedData странице канала и передаваемые в запросе переменные. Алгоритм можно узнать при разборе JS. Этот алгоритм мы используем и будем автоматически подписывать запросы. Для этого нам нужно извлечь rhx_gis параметр.
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer\.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится id канала
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: chid
# Находим элемент в котором хранится rhx_gis
- find:
path: rhx_gis
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: rhxgis
# Находим элементы записей и итерируем по ним
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL на первую подгрузку
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Устанавливаем счетчик подгрузок в 0
- counter_set:
name: pages
value: 0
# Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:После запуска в логе мы можем увидеть вот такую структуру, с которой нам нужно работать:
qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz
US
1.5
480
360
profilePage_25025320
Discovering — and telling — stories from around the world. Curated by Instagram’s community
team.
false
false
http://blog.instagram.com/
http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M
230937095
false
197
false
Instagram
false
false
25025320
false
true
5014
GraphVideo
false
607
1080
https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg
573448
Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous
4709
1688175842423510712
true
25025320
Bdtmvv-DJa4
1515466361
150
150
https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
240
240
https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
320
320
https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
480
480
https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
640
640
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
2516274
...
AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ
true
45ca3dc3d5fd
true
Мы намеренно укоротили исходный код, убрав повторяющиеся элементы. Теперь мы можем описать логику парсинга всех нужных нам полей, а также добавить ограничитель на количество подгрузок, скажем, 10. Также мы добавим паузу, для менее агрессивного парсинга. В результате мы получим финальную версию нашего парсера Instagram.
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer\.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится id канала
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: chid
# Находим элемент в котором хранится rhx_gis
- find:
path: rhx_gis
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: rhxgis
# Находим элементы записей и итерируем по ним
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL на первую подгрузку
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Устанавливаем счетчик подгрузок в 0
- counter_set:
name: pages
value: 0
# Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:
- sleep: 3
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: edge_owner_to_timeline_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то проверяем счетчик подгрузок, больше ли он 10
- counter_get: pages
- if:
type: int
gt: 10
else:
# Если нет, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL следующей подгрузки
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Находим элементы записей и итерируем по ним
- find:
path: edge_owner_to_timeline_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Увеличим счетчик подгрузок на 1
- counter_increment:
name: pages
by: 1Теперь мы пожем перевести наш диггер в Активный режим и запустить его. Как результат в вашем наборе данных будут подобные записи.
[{
"item": {
"caption": "Photo by @williamk\nOut with the old, in with the new. ? #TheWeekOnInstagram",
"comments": "5073",
"likes": "571325",
"url": "https://scontent-sjc3-1.cdninstagram.com/vp/d064d34902bbaba17456da7043307001/5ADF67CC/t51.2885-15/e35/26066810_1561269847323081_4659907128088068096_n.jpg",
"video": "false"
}
}
,{
"item": {
"caption": "Photo by @thatbloom\n“I waited. I waited a lot,” says Roland Kraemer (@thatbloom), who knelt patiently in the snow to capture this moment. “I was inspired by the fact that you don’t necessarily have to travel far to take good photos. This was taken almost in my backyard.” #TheWeekOnInstagram",
"comments": "10468",
"likes": "1235401",
"url": "https://scontent-sjc3-1.cdninstagram.com/vp/4782daed87f1da6d3f22f6d02e2730fa/5AF16142/t51.2885-15/e35/26152364_141930706473591_386722995680313344_n.jpg",
"video": "false"
}
}
,{
"item": {
"caption": "Photo by @tiagoovarjao\nLate afternoon light, good friends and the ocean. ? #TheWeekOnInstagram",
"comments": "4280",
"likes": "708045",
"url": "https://scontent-sjc3-1.cdninstagram.com/vp/8f95ddb0d51ff26a11fa19df3d22d51a/5AEDD312/t51.2885-15/e35/26225106_1942276889134646_4232956111503753216_n.jpg",
"video": "false"
}
}]
Надеемся что данная статья поможет вам в изучении мета-языка и теперь вы сможете решать задачи по парсингу страниц с подгрузкой без затруднений. В качестве домашнего задания, попробуйте разобраться с тем как работает версия парсера для поиска по хэштегам. Ниже приведим код парсера:
---
config:
agent: Firefox
debug: 2
do:
# Инициальзируем переменную в которую записываем hashtag
- variable_set:
field: tag
value: beard
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/explore/tags/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка Consumer.js
- if:
match: Consumer\.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: T\.pagination\},queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится rhx_gis
- find:
path: rhx_gis
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: rhxgis
# Находим элементы записей и итерируем по ним
- find:
path: entry_data > tagpage > graphql > hashtag > edge_hashtag_to_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: entry_data > tagpage > graphql > hashtag > edge_hashtag_to_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL на первую подгрузку
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22tag_name%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: ':{"tag_name":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Устанавливаем счетчик подгрузок в 0
- counter_set:
name: pages
value: 0
# Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:
- sleep: 3
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: edge_hashtag_to_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то проверяем счетчик подгрузок, больше ли он 10
- counter_get: pages
- if:
type: int
gt: 10
else:
# Если нет, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL следующей подгрузки
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22tag_name%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: ':{"tag_name":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Находим элементы записей и итерируем по ним
- find:
path: edge_hashtag_to_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Увеличим счетчик подгрузок на 1
- counter_increment:
name: pages
by: 1
это тема! спасибо!
query_id не меняетя, его не обязательно парсить, это так, на будущее, а так спасибо за статью
Спасибо за замечание. Это конечно же упрощает написание парсера. Однако нашей целью является научить человека писать парсеры самостоятельно, а момент парсинга какого-либо id из подгружаемых файлов как сам факт достаточно важен, чтобы исключать его из статьи. Поэтому оставим статью как есть. Для тех же, кто использует парсер в продакшине, можно использовать совет Вячеслава и использовать статический теперь уже query_hash.
у меня не работает
error Cannot parse JSON: unexpected EOF
Немного изменилась разметка, поправили статью, спасибо 🙂
Михаил, подскажите, а данный способ подойдёт для парсинга нет всех записей аккаунта инстаграма, а для конкретной записи, если я укажу ссылку на конкретную страницу (фотографию) в инстаграм?
К сожалению, нет. Данная конфигурация работает по определенной логике и решает задачу забора данных с бесконечной подгрузкой. Для отдельной страницы нужно будет писать свою логику.
Добрый день подскажите пожалуйста, можно ли парсить все фото канала, а не только 12?
Конечно, в базовом парсере, представленном здесь забирается ограниченное число записей в канале. Это число можно увеличить изменив строку 183. Однако мы обнаружили, что Инстаграм изменил что-то на странице. Сегодня в течении дня мы внесем изменения в статью, чтобы она соответствовала действительности.
Статья обновлена, произошли изменения в системе авторизации публичного API.
«возьмем URL с параметрами, который использовался для загрузки данных <…> Вставим его в адресную строку браузера и нажмем Enter. Мы увидим как загрузится страница в JSON формате»
Не грузится, выдаёт «403 Forbidden». ЧЯДНТ?
Вы все делаете правильно. Дело в том, что после последнего апдейта API Instagram пропала возможность загрузки фидов напрямую в браузер, поскольку текущая реализация авторизации требует передачи цифровой подписи запроса в заголовке запроса. Спасибо за указание на неточность, текст статьи мы поправили.
Здравствуйте, очень понравилась статья! Хотелось бы узнать : можно ли так же сделать с определенными хештегами ?
Да. конечно, это возможно. Правда для этого придется брать QueryID из другого файла, менять в запросе variables и соответственно подпись, а также пути к контейнерам с данными. Я прикрепляю к статье версию парсера для хэштэгов. Можете запустить его и разобраться с тем как он работает самостоятельно.
Извините, но я не могу найти прикрепленную версию парсера для хэштегов. Не могли бы вы, пожалуйста, отправить мне на почту:,)
а что нужно поменять в парсере, чтобы он работал не с определенными профилями, а с хештегами
ой , случайно второй раз спросила
Добрый день!
Скажите, почему при выполнении сценария для хэштегов парсится определенное количество записей (разное для разных тэгов), и при этом, данное число записей остается прежним и после изменения строки 197 и после изменения строки 217?
Изменять нужно только значение в строке 197, это регулирует количество забранных страниц с результатами поиска (по 12 записей на каждой странице). Однако с парсером есть проблема в данный момент, изменилось месторасположение queryId в JS. В статью и парсер внесены изменения.
Добрый день! Как исправить: при выполнении сценария с хэштэгом парсится определенное количество записей (не все), при этом на это количество не влияет ни изменение строки 197, ни изменение строки 217 и 159?
Изменять нужно только значение в строке 197, это регулирует количество забранных страниц с результатами поиска (по 12 записей на каждой странице). Однако с парсером есть проблема в данный момент, изменилось месторасположение queryId в JS. В статью и парсер внесены изменения.
Михаил, большое спасибо за статью, очень полезна. По ней я сейчас пытаюсь написать аналогичный парсер на C#, но в одном месте застопорился.
# Формируем подпись и записываем ее в переменную signature
— register_set: ‘:{«tag_name»:»»,»first»:12,»after»:»»}’
— normalize:
routine: md5
Насколько я понял, тут идет преобразование текста в XML, а потом преобразование в md5 хеш.
До перевода в XML у меня текст:
adf9ce39c932f9f1938f2505a820d1a7:{\»tag_name\»:\»2177703770\»,\»first\»:12,\»after\»:\»QVFBcXNMUVZ4aHV0UGpqLVlhbHdTMExpNW9EZmM5Mkg2RlhJSVFxSXYyQXZCa0lIcU14Sk5IbU9zdWpHU0FTalg2QkplbnFvOHp5YW1Gcm9wbGtGOThYcw==\»}
Перевести в XML такую строку нельзя, поэтому поставил скобки { } в начале и конце.
После перевода в XML получился вот такой текст:
«217770377012QVFBcXNMUVZ4aHV0UGpqLVlhbHdTMExpNW9EZmM5Mkg2RlhJSVFxSXYyQXZCa0lIcU14Sk5IbU9zdWpHU0FTalg2QkplbnFvOHp5YW1Gcm9wbGtGOThYcw==»
А его я уже преобразую в MD5.
B8D1BA84EB7B6CCFDA87CB6A6616A855
Добавляю в запрос заголовки:
request.Headers.Add(«x-instagram-gis», hash);
request.Headers.Add(«x-requested-with», «XMLHttpRequest»);
Делаю запрос и получаю
403 ошибку(
Помогите пожалуйста найти причину.
Добрый день. Нет, здесь идет формирование подписи для передаваемых в запросе параметров. Сначала мы в регистре формируем JSON строку (payload), а затем генерируем MD5 для этой строки. XML там нет.
Ой. Ошибся. После перевода в xml получился вот такой текст:
217770377012QVFDWlhyMzhwbWEwblJSc0JYY1laZk01TUVpbklfYmZTcTdhLW82ZmM2cWZRdFE2Ym93ejlHRnZ4QmhFeUM2MG0tbVFJQUV0Ukk5bWh3dXJXZUFqbGtfeA
Прочитайте комментарий выше, в XML ничего не нужно преобразовывать. MD5 надо брать для сформированной в формате JSON строки.
Михаил, большое спасибо) У меня все получилось)
Всегда пожалуйста, рад за Вас 🙂
Михаил а как query_hash сразу взять из headers и записать в переменную?
Дмитрий, query_hash приезжает в JS файле, в заголовках его нет, поэтому прочитать его оттуда не получится.
А как насчет этой ссылки? Здесь в json формате
https://www.instagram.com/data/shared_data/
А что интересного есть там? Вообще Diggernaut преобразовывает JSON в XML, а затем можно использовать стандартные команды find чтобы проходить в блоки.
Михаил, добрый день!
Спасибо вам огромное за статью! Очень помогает в изучении.
Сейчас пишу на python
До этого написал парсинг с помощью selenium, но времени убивает очень много.
Решил окунуться в запросы. И вроде бы все окей, все переменные вытащил но не могу отправить нормальный запрос на сервер.
Можете по подробней описать что происходит в коде с 149 по 172.
В каком виде должен уходить запрос. Я не совсем понял. А попытки прописать все в headers закончивались 403 ошибкой
Добрый день, Павел. Запрос который мы отправляем (параметр variables который мы передаем в HTTP запросе) отправляется в виде stringify JSON, а именно:
{"id":"<%chid%>","first":12,"after":"<%cursor%>"}, где<%chid%>надо заменить на ID канала, а<%cursor%>— на курсор последней показанной записи. Полученное значение перед отправкой нужно закодировать в URLEncode поскольку запрос у нас будет GET и многие символы значения недопустимы в URL. Затем мы составляем строку, для которой нужно посчитать сигнатуру. Эта строка в таком же stringify JSON формате (только без URLEncode), и выглядит она как то так:<%rhxgis%>:{"id":"<%chid%>","first":12,"after":"<%cursor%>"}, где<%rhxgis%>— значение параметра rhx_gis (который вы должны были извлечь ранее), остальные поля и значения те же что и в запросе. На полученную строку применяем функцию MD5 и получаем подпись в HEX формате. Эту подпиcь мы используем в заголовке запроса:x-instagram-gis: <%signature%>. Очень важно чтобы для всех запросов использовался одинаковый user-agent, поскольку rhx_gis базируется на его значении, часто многие забывают в одном из запросов использовать user-agent и поэтому ключи а соответвенно и подписи не совпадают, а значит нас ждет ошибка 403.Здравствуйте, у вас, случаем, нет идей, где может закрасться проблема при реализации этого на Python?
Проверил уже все, что возможно, всё равно при попытки отправки запроса с собранной подписью и параметрами, получаю в ответ 403.
Добрый день, Сергей. Самая частая ошибка — отправка в запросах разных user-agent. Второе — некорректный подсчет контрольной суммы. Пришлите ссылку на репозиторий с кодом, мы посмотрим и попробуем помочь.
Михаил, добрый день! Добавил в Ваш скрипт парсинг id по аналогии с парсингом количества лайков:
— find:
path: owner > id
do:
# Парсим содержимое элемента
— parse
# Записываем значение в поле объекта item
— object_field_set:
object: item
field: id
Проблема в том, что id парсятся только для первых 70+ записей. Подскажите, в чем может быть дело?
Здравствуйте, Алексей. Сразу так сложно сказать. Свяжитесь с нами через онлайн чат на сайте и сообщите ID Вашего диггера. Мы посмотрим и дадим ответ.
Похоже опять не работает. Нужен x-ig-app-id, а x-instagram-gis уже нет. Не получается никак ((
Добрый день, Артем. Не совсем понятно о чем идет речь. Парсер из статьи прекрасно работает, в демо версии собирает 156 записей.
Большое спасибо за статью, очень познавательно. Особенно интересно было это читать после того, как я сам написал похожий парсер, ход изучения работы инстаграмма очень был похож на то, что делал я сам, но у меня меньше опыта и поэтому заняло больше времени.
Но это все хорошо для открытых аккаунтов. А как насчет закрытых? То есть если у меня есть аккаунт в инстаграмме, для которого открыт аккаунт, данные которого надо спарсить — как это реализовать? Иными словами — как сэмулировать авторизацию в инстаграмме?..
(Сам я пишу на PHP с cUrl, если что).
Можно посмотреть в этой статье Как собирать данные о компаниях в инстаграм без мобильного приложения, там есть блок авторизации
Добрый день, спасибо за статью. Пытаюсь получить список людей кто поставил лайк, так вот там используется другой query_hash, которого нет в ProfilePageContainer.js…
Просканировал весь список .js файлов и нигде не обнаружил нужного мне query_hash (он же queryId)
у вас нет идей откуда он берется?
Добрый день, посмотрите в https://www.instagram.com/static/bundles/es6/ConsumerLibCommons.js
Здравствуйте. А что скажете насчет получения параметра _signature для ТикТок? Его нету в исходнике, оно генерируется. Как думаете, как его можно получить?
Добрый день, изучить работу JS и сгенерировать
Здравствуйте! При переходе по https://www.instagram.com/graphql/query/?
query_hash=df16f80848b2de5a3ca9495d781f98df&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12% (URL из вашего примера), вместо JSON c AFTER получаю {«message»: «Variables are invalid JSON.», «status»: «fail»}. Скопировал все верно. В чем может быть причина неудачи?
%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12% — эта часть не выглядит полной (в статье например это приведено так %7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%2C%22after%22%3A%22AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A%22%7D). Если сделать URLDecode на Ваш параметр, то мы получим инвалидный JSON, о чем и пишет Instagram:
Возможно Вы хотели передать
В этом случае параметр должен быть таким: %7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%7D
Для декодирования и кодирования URLEncode можно пользоваться этим сервисом: URLEncoder
Здравствуйте! При переходе на URL https://www.instagram.com/graphql/query/?query_hash=df16f80848b2de5a3ca9495d781f98df&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12% (из вашего примера) вместо того, чтобы получить AFTER получаю {«message»: «Variables are invalid JSON.», «status»: «fail»}. Правильность введенных данных проверил, различные эксперименты приводят к этому же результату. Как можно выйти из ситуации и в чем собственно проблема?
Спасибо за ответ, тогда видимо я не совсем понял, как получаем значение первого AFTER. Какой должен быть URL, чтобы получить именно первый AFTER?
Не заметил дополнение вашего комментария. Я все понял, большее спасибо)
с Youtube такой фокус не прокатит?
Youtube надо разбирать отдельно, там другие скрипты и другая логика.
Спасибо, мужик) За 5 минут по твоей статье понял как парсить сайты с js, и главное без богомерзких браузеров, а чисто запросами. Все бы так понятно и информативно писали
Огромное спасибо за описание поиска запросов через Chrome Dev Tools. Весь интернет облазил, а нашел у Вас. Еще раз ОГРОМНОЕ спасибо за статью! Успехов Вам во всех делах и всяческих благ!