Как создавать сценарий парсера для сайта с помощью специального приложения Excavator мы уже видели. Давайте теперь попробуем написать сценарий (config) самостоятельно, с помощью нашего мета-языка для парсинга (SML — Scraping Meta Language). Это не сложно и, как позже вы сможете заметить, достаточно быстро. В качестве сайта для примера мы возьмем нашу тренировочную площадку sandbox.
«Песочница» достаточно простая, есть табличные данные, небольшой пагинатор (пронумерованные страницы, которые можно листать, кликая на них) и странички с какими то деталями (details). Для написания сценария диггера нам потребуется регистрация в сервисе Diggernaut, созданный проект и диггер.

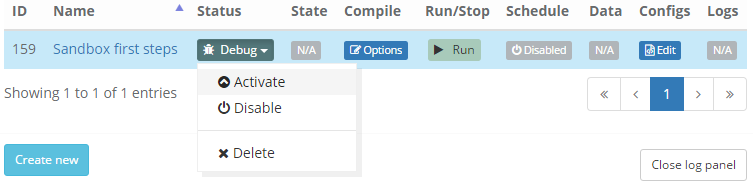
У нас уже создан проект Project #2 и диггер Sandbox first steps. Все диггеры по умолчанию во время создания имеют статус Debug.
В режиме Debug диггер получает отладочную информацию с сервера и пишет её в лог, который затем является основой для анализа работы сценария диггера и выявления ошибок. Чуть позже мы вернемся к этому моменту, а сейчас давайте откроем редактор сценариев, нажав на кнопку + Add в колонке Configs.
Вы увидите открывшийся редактор кода, в котором мы с вами будем писать наш сценарий, используя язык разметки YAML.
Редактор имеет подсветку кода, настраиваемые стили, шрифты и так далее. Вы можете самостоятельно поиграться с этими параметрами и остановиться на том, что вам более комфортно.
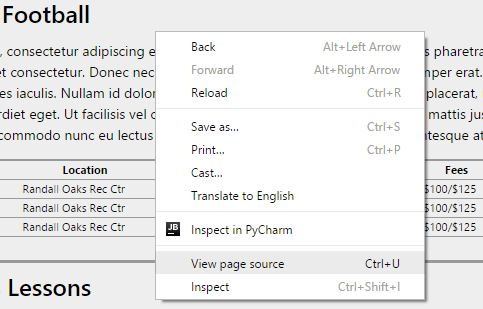
Прежде, чем приступать к написанию сценария для любого парсера, вы должны изучить сайт источник, понять, как он получает данные и найти возможность извлечь эти данные. Поскольку наша «песочница» достаточно простая и не использует какие-либо виды динамической подгрузки содержимого, изучение работы сайта не займет много времени. Для изучения мы будем использовать браузер Chrome и встроенный в него инструмент Developer Tools, который можно вызвать комбинацией клавиш Ctrl + Shift + I.
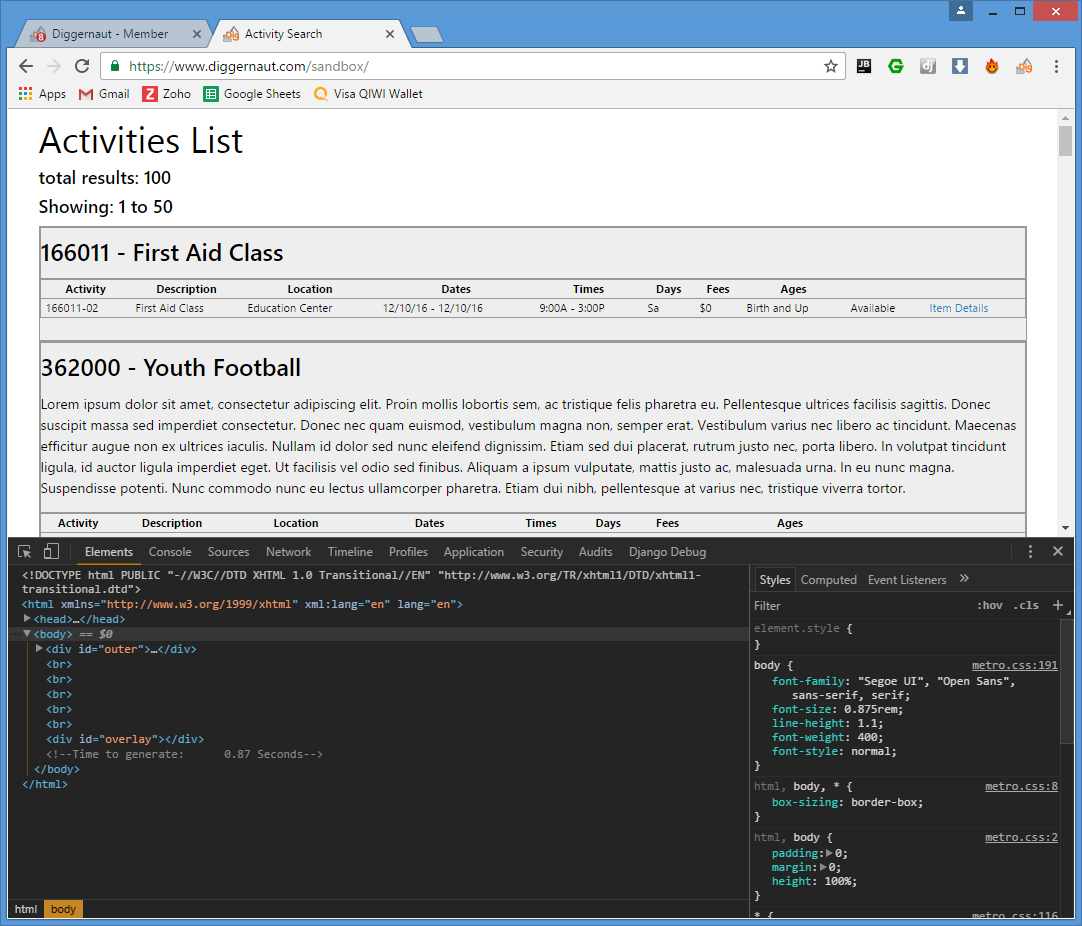
Для более полного понимания происходящего вам необходимо иметь хотя бы начальные знания в языке разметки HTML, языке описания стилей CSS и, желательно, азы языка программирования JavaScript, который в данной статье вам не пригодится, но весьма поможет в дальнейшем, если вы захотите получить данные сайтов с динамической подгрузкой. Также, вероятнее всего, вам потребуются знания регулярных выражений, если вы захотите извлечь какие-то данные из уже найденного блока. Более подробно про регулярные выражения можно прочитать здесь или здесь.
Итак, мы планируем забрать следующие поля:
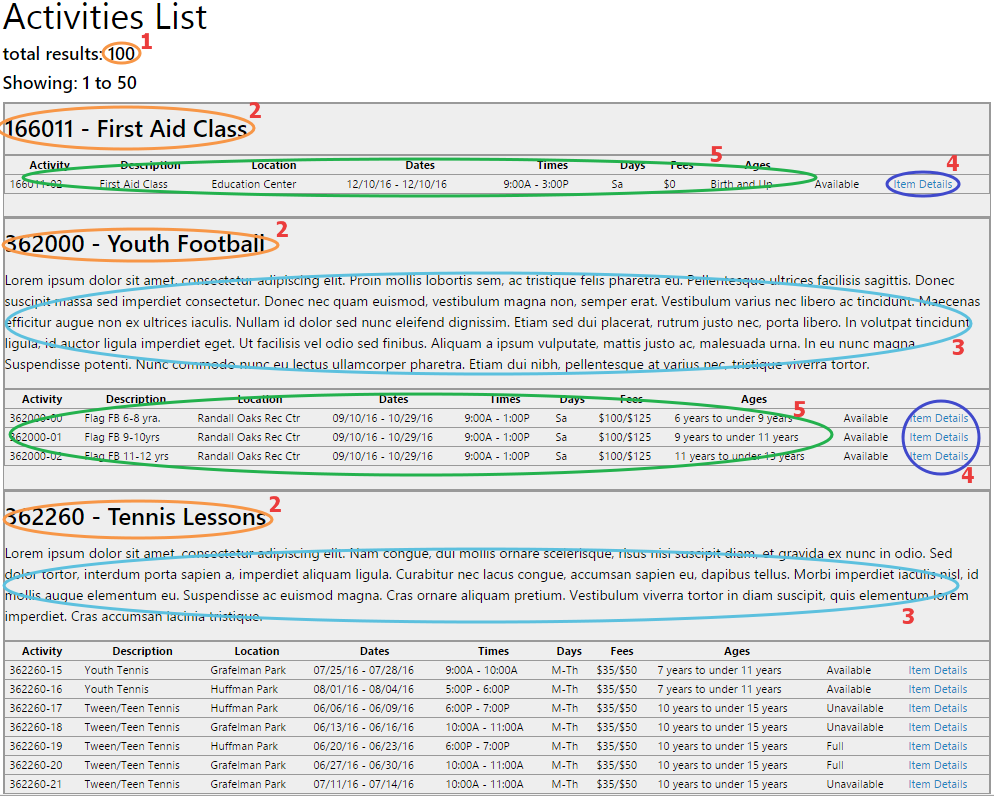
1 — цифру общего количества записей
2 — названия Классов (Class)
3 — какое-то описание Класса, если оно есть
4 — пройтись по ссылкам каждой записи к описанию каких-то деталей
5 — забрать какие-то данные по каждому Мероприятию (Activity) в текущем Классе
После прохода по первой странице сайта мы заберем следующую страничку из пагинатора:
![]()
и повторим цикл сбора данных уже для следующей страницы.
Со странички деталей мы заберем поля:
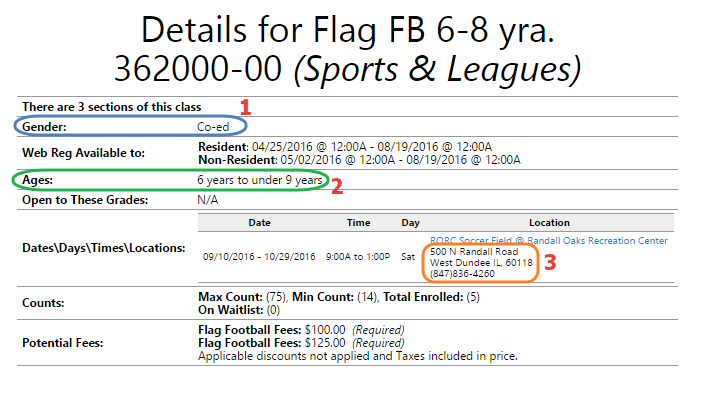
1 — пол (мальчики отдельно, девочки отдельно), Co-ed — все вместе
2 — возраст будем брать здесь, а не с центральной страницы
3 — полный адрес и здесь же попробуем вытащить номер телефона
Основные поля определены, приступим непосредственно к самому сайту.
Первое, что мы будем вытаскивать, это счетчик всех записей, равный 100, и находится он в HTML теге заголовка h4.

Посмотрим внимательно на код страницы сайта. Нужная нам цифра находится в теге h4, но следом за этим тегом у нас идет еще один заголовок h4. Каким же образом забрать нужную цифру из первого тега? Это можно сделать тремя способами:
Поскольку мы предполагаем, что нужный нам тег h4 всегда содержит в себе текст total results:, то мы можем использовать это для прохода к тегу по содержимому. Для этого используется специальная команда tag:contains('sample text'), в нашем случае это будет h4:contains('total results'). Еще, как вариант, пройти по этому пути можно через div#content > h4:first-child.
Необходимый нам тег имеет класс, отличный от второго тега h4. Это также можно использовать для прохода к нужному элементу через h4.right.
Использовать вышестоящий тег div с атрибутом ID=content как якорь, и, отталкиваясь от него, выйти на первый h4, ограничив поиск только первым найденным h4 командой 'div#content > h4:first-child' (обратите внимание, вся команда забрана в одинарные кавычки, поскольку присутствует символ #, который в YAML считается комментарием)
И, как дополнительный бонус, можно поступить проще, использовав возможности инструментов разработчика браузера Chrome :)
Для этого нажимаем на нужный нам элемент правой кнопкой мышки и выбираем Copy -> Copy selector
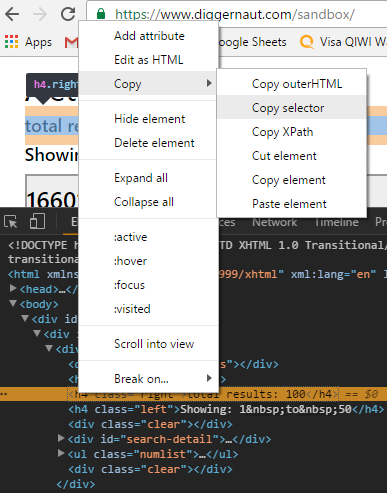
Вот так будет выглядеть скопированный текст: Для проходов к нужным нам элементам сайта мы используем специальные CSS селекторы (Selectors). Более подробно ознакомиться с ними можно здесь и здесь. Теперь давайте напишем это в виде сценария и посмотрим, что у нас получится (полный текст сценария будет представлен в конце статьи). И отдельно в виде текста, если вы захотите скопировать и поэкспериментировать самостоятельно (далее я буду приводить только тексты кода): Рассмотрим код по шагам. Т.е., по сути, мы сказали парсеру: “перейди по этому адресу URL и найди элемент вот по этому пути”. Сохраняем наш сценарий, нажав на кнопку После отработки сценария строка состояния парсера изменится, теперь у нас появится активная кнопка Откроется окно с сообщениями о ходе выполнения сценария, давайте посмотрим более детально, что и как у нас происходило. По умолчанию сортировка включена по полю Time, от более раннего времени к более позднему. Следовательно, начало работы сценария у нас будет начинаться снизу. Уровень сообщений До нужного блока с числом сообщений мы добрались успешно, теперь нам нужно убрать текст и выдернуть непосредственно само число. Это делается следующим образом: Мы добавили несколько новых команд в наш сценарий. Мы применяем эти команды для того, чтобы запомнить цифру количества записей, чтобы чуть позже вернуться к ней перед записью в базу. Давайте запустим и посмотрим результат работы в логе. У нас появились новые строки: Мы получили то, что хотели в виде переменной, которую будем использовать дальше. Теперь попробуем забрать все названия Классов. Если мы продолжим изучение исходной страницы сайта, то мы обнаружим, что все блоки, принадлежащие Классам, описаны тегами Наш путь будет выглядеть так: В этом примере блок Выполним и заглянем в лог. На первой странице найдено 23 блока с описанием Классов. Здесь же мы можем заглянуть в первый попавшийся на пути сценария блок. Все данные по Классу перед нами. Часть из них лежит отдельно в теге Давайте учтем этот момент и дополним наш сценарий. У нас добавились две новых переменных: Следующим шагом мы создаем основной цикл: Это главный рабочий цикл, в котором будут происходить все основные действия по работе с Классом нашего сценария. Здесь мы будем забирать оставшуюся часть данных из таблицы, делать переход на страницу с деталями и забирать данные оттуда, а также записывать в базу данных полученные результаты. Мы специально вставили два оператора Первая команда, стоящая в основном цикле сценария, это Находясь в основном цикле и проходя по каждому элементу В следующей ячейке мы забираем информацию по датам Мероприятия. Обратите внимание, мы используем сперва фильтр и выражение regex для забора первой части даты, затем таким же блоком кода, но с другим регулярным выражением, мы забираем вторую часть даты. После извлечения даты мы используем специальную команду нормализатора, которая превращает дату формата сайта в формат, необходимый нам. Затем мы записываем полученный результат в хранилище На первом участке лога видно, что найден блок с диапазоном дат, к которому затем применяется фильтр с регулярным выражением. Далее производится выделение нужной даты по входящему шаблону и преобразование полученного результата в нужный нам формат. Здесь нужно отметить, что исходный линк на странице представляет собой относительный путь и выглядит так: В таком виде Здесь нужно обратить внимание, каким образом собираются данные по адресу и телефонному номеру. Приведенный код сценария лишь один из вариантов решения задачи. Для прохода к нужной ячейке основной таблицы мы используем команду первый из которых содержит ненужную нам информацию и мы просто отсекаем этот тег командой В итоге мы получаем следующий блок: Запишем его в хранилище, после чего просто удалим элемент с телефоном из блока командой Для сбора адреса в одну строку, мы просто применим команду Теперь можно убрать команды Осталось только прикрутить бродилку по пагинатору и сценарий диггера готов. Для этого немного поменяем начало нашего сценария и добавим следующие команды: Здесь все очень просто, мы находим элемент в котором имеется ссылка на следующую страницу пагинатора и добавляем ее в массив paginator. При следующей итерации цикла обхода страниц, будет осуществлен переход по новой ссылке, поиск следующей страницы пагинатора и так далее. Все, сценарий для нашей песочницы написан. В качестве завершающего шага вы можете переключить диггер в режим запустить на исполнение и по завершению перейти в раздел данных, где вы сможете забрать их в нужном для вас формате. Полный код сценария вы можете забрать здесь. Happy digging!#content > h4.right. Для добавления данного пути в сценарий диггера завернем всё это в кавычки и добавим div в начало строки: 'div#content > h4.right'. В этом случае путь обхода начинается от родительского элемента . Но учтите, Chrome вносит собственные исправления в HTML код, и может оказаться так, что в инструменте разработчика вы видите, как пример, тег , а в оригинальном HTML коде его нет. Лучше всего дополнительно подвериться, просто открыв исходный код страницы в самом браузере.
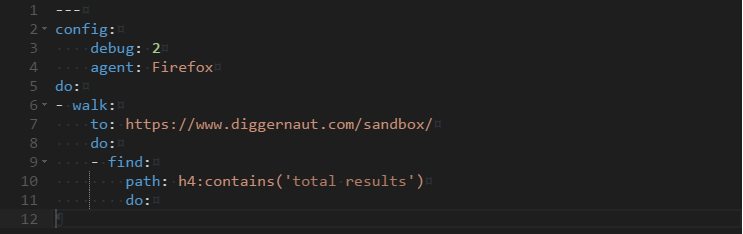
---
config:
debug: 2
agent: Firefox
do:
- walk:
to: https://www.diggernaut.com/sandbox/
do:
- find:
path: h4:contains('total results')
do:
Первое, на что нужно обратить внимание, язык “не” разметки YAML (Ain’t Markup Language), придерживается строгих правил отступов. Если команды находятся не под нужными блоками и без необходимых отступов — будут проблемы. Сценарий начинается с трех символов тире ---, это разделитель между директивами и содержимым документа. В нашем случае это просто индикатор начала документа сценария, поскольку дополнительных директив мы не используем.debug: 2 — этой командой мы включаем дополнительное отображение содержимого страниц в логе, что позволяет более детально видеть логику работы диггера. В настоящий момент сервис поддерживает три уровня отладки:
0 — уровень по умолчанию, выводит только общую информацию
2 — выводит в лог еще и содержимое страницagent: Firefox — этой командой сообщаем сайту о том, что мы работаем от лица браузера Mozilla Firefox, команда не является обязательной, но ряд сайтов отказывается обрабатывать запросы, если мы не обозначим тип браузера.do: — это начало нового, логического блока команд. Все последующие команды, находящиеся на одном с блоком уровне, являются принадлежащими этому блоку.- walk: — команда перехода по адресу URL или специальному массиву (pool) адресов URL с использованием GET или POST. Эта команда состоит из дополнительных параметров:to: — здесь мы указываем линк, на который нужно перейти иdo: — начало нового блока команд, выполнение которых произойдет сразу после успешного перехода по линку- find: — это основная команда, которая осуществляет поиск нужного нам элемента или блока элементов на странице, по указанному в параметреpath: — пути, в нашем случае это h4:contains(‘total results’) и выполнением блокаdo: — с набором команд, в случае, если поиск был успешнымSave и попробуем его запустить. Для запуска парсера необходимо нажать на кнопку пуска в колонке Run/Stop
Show в колонке Logs, на которую мы и нажмем.
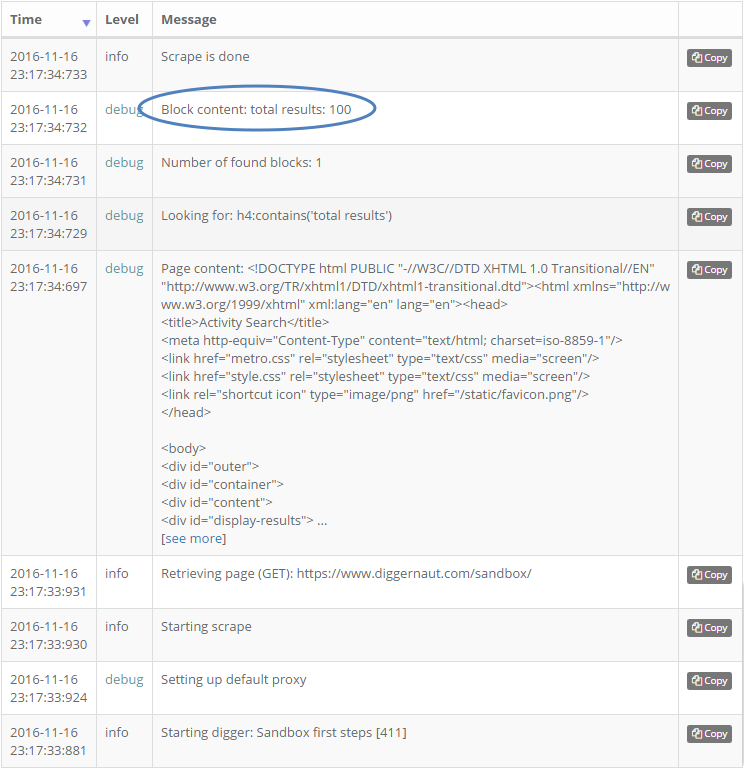
INFO, мы видим первую запись Starting digger: Имя диггера [идентификатор диггера]. Далее идет подключение дефолтного прокси сервера и начало парсинга. Retrieving page (GET) сообщает нам о том, что начала работать команда walk, которая осуществляет переход по нужному нам URL. А вот следующий блок с уровнем DEBUG уже представляет интерес для нас, поскольку в нем содержимое полученной страницы. По сути это голый HTML, который получает движок сервиса при переходе по указанному URL. Это нужно принимать во внимание, поскольку навигация по CSS селекторам осуществляется именно по этому HTML коду, а не тому, что мы можем видеть, если откроем исходный текст страницы в браузере. Часто бывает так, что исходный текст HTML не совпадает с тем, что мы видим в браузере. Это особенно касается сайтов, на которых осуществляется динамическая подгрузка данных. Подобные случае мы рассмотрим отдельно, в рамках другой статьи. А сейчас мы просто перейдем к следующему блоку сообщений, в котором стоит Looking for: h4... это начала работать команда сценария: path: h4:contains('total results') и, как мы видим в блоке выше, Number of found blocks: 1, мы нашли то, что нужно и передали в последующий блок do: содержимое в виде: total results: 100.---
config:
debug: 2
agent: Firefox
do:
- walk:
to: https://www.diggernaut.com/sandbox/
do:
- find:
path: h4:contains('total results')
do:
- parse:
filter:
- results:\s*(\d+)
- variable_clear: number_of_results
- variable_set: number_of_results
- stop- parse: — это команда разбора пришедшего в текущий блок do: результата работы команды path: К этому результату мы применяем один фильтр filter:, в виде последовательности regex, для выделения числа из строки, указанной в параметре — results:\s*(\d+). Если кратко, то это регулярное выражение ищет в пришедшем блоке текста строку results: с неизвестным количеством пробелов после двоеточия и затем какой то набор состоящих из одной и более цифры, объединенных в группу через скобки (), именно результат, полученный в этих скобках, перейдет на следующий оператор- variable_clear: number_of_results — это команда очистки переменной и следующая- variable_set: number_of_results — это команда записи в переменную- stop — это просто левая команда, которая порождает ошибку исполнения и применяется для экстренной остановки работы сценария.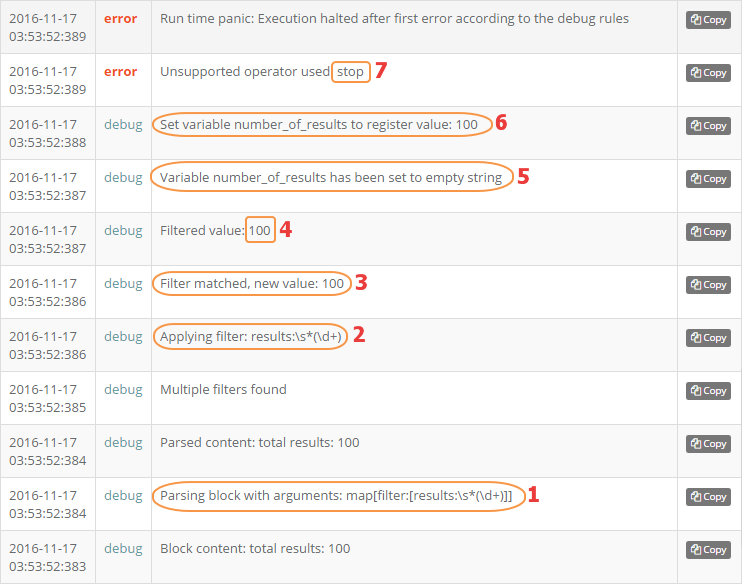
1 — это начало работы команды filter с указанным параметром
2 — попытка применить фильтр к результату, полученному от команды find->path
3 — фильтр успешно применен
4 — найдено значение 100
5 — происходит очистка внутренней переменной number_of_results
6 — в переменную number_of_results присваивается значение 100
7 — выполняется не поддерживаемая команда STOP, что приводит к остановке сценария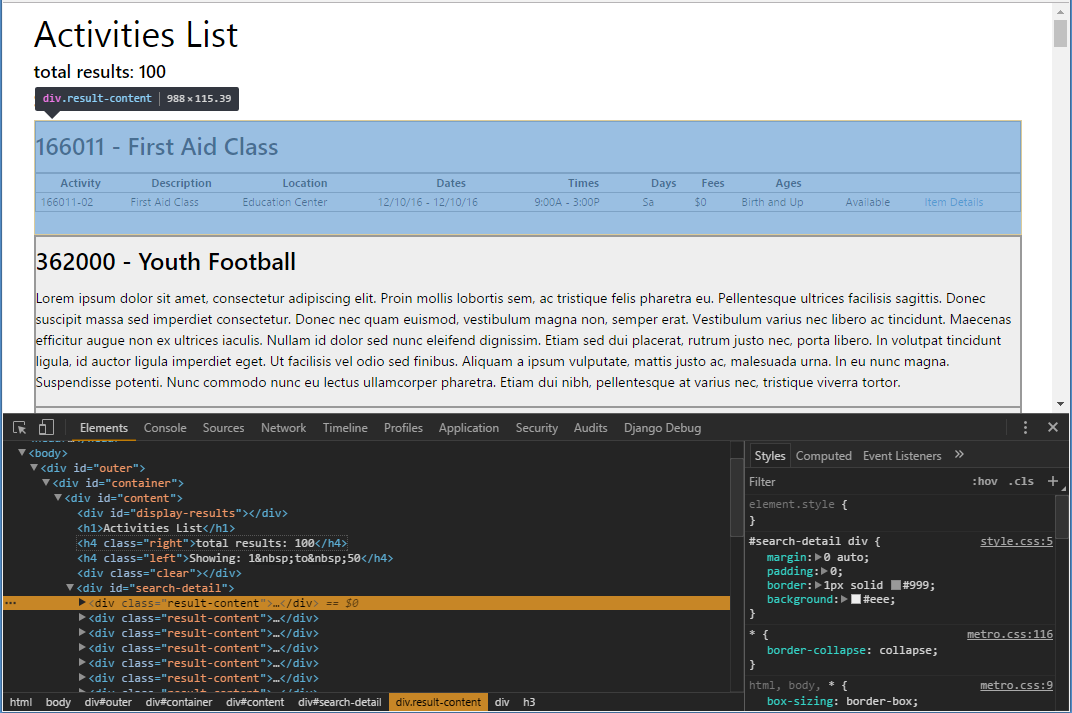
id="". Если создатели сайта соблюдают правила, то этот идентификатор будет являться уникальным на странице и построить путь от него будет достаточно просто. Бывают тяжелые случаи, когда множество объектов на странице имеют одинаковый id или id создаются самим сервером в процессе работы, тогда путь придется строить от более очевидного тега с уникальным классом внутри или последовательной группой тегов.
'div#search-detail > div.result-content' (а можно использовать и альтернативу этому пути в виде .result-content). Запишем его в сценарий.---
config:
debug: 2
agent: Firefox
do:
- walk:
to: https://www.diggernaut.com/sandbox/
do:
- find:
path: h4:contains('total results')
do:
- parse:
filter:
- results:\s*(\d+)
- variable_clear: number_of_results
- variable_set: number_of_results
- find:
path: 'div#search-detail > div.result-content'
do:
- stopdo:, идущий после path: 'div#search-detail > div.result-content', будет повторяться по числу найденных блоков. Таким образом, это цикл, в котором мы будем обрабатывать данные по каждому блоку Класса.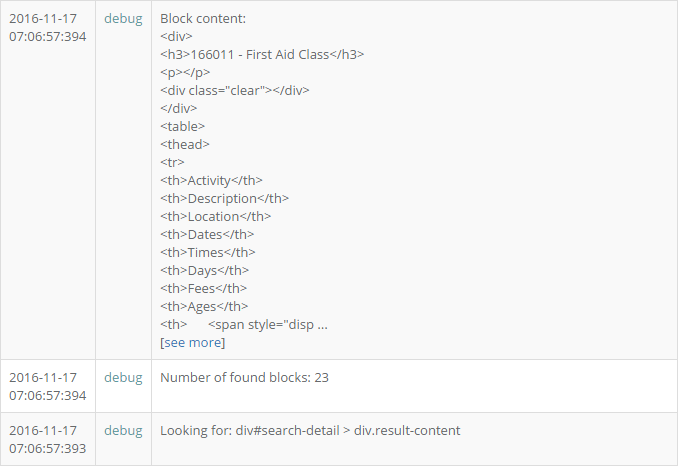
Он же, но в Chrome developer tools: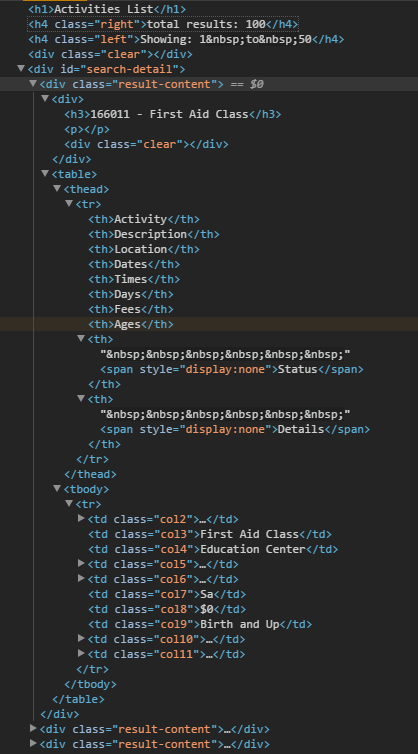
div, часть данных находится в таблице с заголовками. Обратите внимание, в первом Классе всего одно Мероприятие в таблице! Нам же, нужно вытащить все Мероприятия для каждого Класса, а заодно и общую информацию.
---
config:
debug: 2
agent: Firefox
do:
- walk:
to: https://www.diggernaut.com/sandbox/
do:
- find:
path: h4:contains('total results')
do:
- parse:
filter:
- results:\s*(\d+)
- variable_clear: number_of_results
- variable_set: number_of_results
- find:
path: 'div#search-detail > div.result-content'
do:
- find:
path: 'h3'
do:
- parse
- variable_clear: class_name
- variable_set: class_name
- find:
path: 'div > p'
do:
- parse
- variable_clear: class_description
- variable_set: class_description
- find:
path: 'table > tbody > tr'
do:
- stopclass_name и class_description, в которые мы поместили название Класса и его описание. Посмотрите внимательно на значения команд path:, в первом случае это h3, во втором 'div > p'. Это очень важный момент, эти пути должны отталкиваться от предыдущего блока path-do (div#search-detail > div.result-content), который служит своеобразным якорем для всех последующих путей блока do:. Загляните в лог, вы увидите сохраненные значения для Set variable class_name to register value: 166011 - First Aid Class и пустое значение для Variable class_description has been set to empty string -> Register is empty, not resetting variable. Поскольку описания для первого класса у нас на странице нет, следовательно, переменная будет пустой.- find:
path: 'table > tbody > tr'
do:---
config:
debug: 2
agent: Firefox
do:
- walk:
to: https://www.diggernaut.com/sandbox/
do:
- find:
path: h4:contains('total results')
do:
- parse:
filter:
- results:\s*(\d+)
- variable_clear: number_of_results
- variable_set: number_of_results
- find:
path: 'div#search-detail > div.result-content'
do:
# --[ CLASS ]---------------------------------------------------------------------
# take name of Class
- find:
path: 'h3'
do:
- parse
- variable_clear: class_name
- variable_set: class_name
# take description of Class
- find:
path: 'div > p'
do:
- parse
- variable_clear: class_description
- variable_set: class_description
# take Class Activities
- find:
path: 'table > tbody > tr'
do:
# prepare new object
- object_new: post
# save main information
- variable_get: number_of_results
- object_field_set:
object: post
field: number_of_results
- variable_get: class_name
- object_field_set:
object: post
field: class_name
- variable_get: class_description
- object_field_set:
object: post
field: class_description
# activity field
- find:
path: 'td.col2'
do:
- parse
- object_field_set:
object: post
field: activity
# date field
- find:
path: 'td.col5'
do:
# date from
- parse:
filter:
- (\d{2}\/\d{2}\/\d{4})\s*-
- normalize:
routine: date_format
args:
format_in: '%m/%d/%y'
format_out: '%Y-%m-%d'
- object_field_set:
object: post
field: date_from
# date to
- parse:
filter:
- \s*-\s*(\d{2}\/\d{2}\/\d{4})
- normalize:
routine: date_format
args:
format_in: '%m/%d/%y'
format_out: '%Y-%m-%d'
- object_field_set:
object: post
field: date_to
# days field
- find:
path: 'td.col7'
do:
- parse
- object_field_set:
object: post
field: days
# fees field
- find:
path: 'td.col8'
do:
- parse
- object_field_set:
object: post
field: fees
- find:
# find a link to details page
path: 'td.col11 > a'
do:
- parse:
attr: href
- normalize:
routine: url
- walk:
to: value
do:
# --[ CLASS DETAILS ]-----------------------------------------------------
# find 1-st field with gender
- find:
path: tr:contains('Gender')
do:
- parse:
filter:
- Gender:\s*(.*)
- object_field_set:
object: post
field: gender
# find 2-nd field with age
- find:
path: tr:contains('Ages')
do:
- parse:
filter:
- Ages:\s*(.*)
- object_field_set:
object: post
field: ages
# find 3-d field with address and phone
- find:
path: tr:contains('Dates\\Days\\Times')
do:
- find:
path: 'td:nth-child(2) > table > tbody > tr > td:nth-child(4) > div'
# taking all divs except first one
slice: 1:-1
# merging divs into one block
merge: div
do:
# parsing for phone number by regex
- parse:
filter:
- (\(\d+\)\s*[\d-]+)
- object_field_set:
object: post
field: phone
# removing last div with phone number
- node_remove: div:nth-child(3)
# concatenate two parts of address with comma+space delimiter
- find:
path: div
do:
- parse
- object_field_set:
object: post
field: address
joinby: ', '
- stop
# --[ CLASS DETAILS ]-----------------------------------------------------
- stop
- object_save:
name: post
# --[ CLASS ]---------------------------------------------------------------------stop, чтобы можно было посмотреть в лог на примере первого блока. Сценарий снабжен небольшими комментариями для указания ключевых моментов. Давайте рассмотрим код сценария более детально.object_new: post
Эта команда обеспечивает вам именованное (вы можете присвоить любое имя хранилищу, в нашем случае это post) хранилище-объект для ваших данных, которые вы сможете затем записать в базу данных. Обратите внимание, что команда записи object_save: должна находиться на том же уровне, что и команда создания. С помощью этой команды можно создавать очень сложные, вложенные структуры данных для любых ситуаций. После создания объекта мы можем записать в него уже собранные ранее данные, что мы и делаем в последующих строках.- variable_get: number_of_results
- object_field_set:
object: post
field: number_of_resultstr таблицы, мы забираем необходимую нам информацию с нужных столбцов td таблицы. Поскольку каждый элемент ячейки таблицы имеет свой собственный класс, мы можем использовать это для адресации.- find:
path: 'td.col2'
do:
- parse- find:
path: 'td.col5'
do:
# date from
- parse:
filter:
- (\d{2}\/\d{2}\/\d{4})\s*-
- normalize:
routine: date_format
args:
format_in: '%m/%d/%y'
format_out: '%Y-%m-%d'
- object_field_set:
object: post
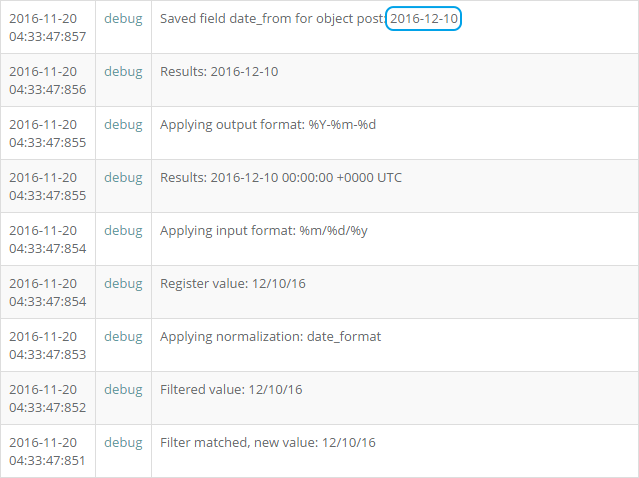
field: date_frompost. Если мы посмотрим лог для этого участка сценария, мы видим следующую последовательность работы (снизу вверх).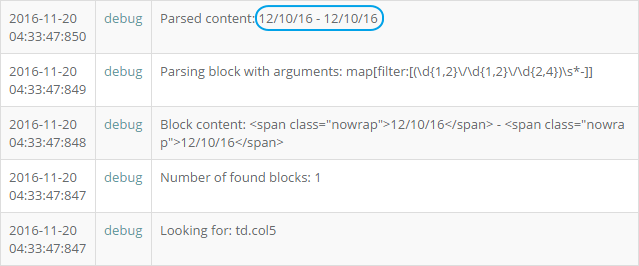
Завершающий блок этого уровня предназначен для извлечения URL адреса для страницы с деталями.- find:
# find a link to details page
path: 'td.col11 > a'
do:
- parse:
attr: href
- normalize:
routine: url
- walk:
to: value
do:![]()
details.html использовать переход мы не можем, поэтому мы применяем нормализацию, и получаем полный линк для перехода: https://www.diggernaut.com/sandbox/details.html, после чего осуществляем переход на страницу с деталями.- find:
path: tr:contains('Dates\\Days\\Times')
do:
- find:
path: 'td:nth-child(2) > table > tbody > tr > td:nth-child(4) > div'
# taking all divs except first one
slice: 1:-1
# merging divs into one block
merge: div
do:
# parsing for phone number by regex
- parse:
filter:
- (\(\d+\)\s*[\d-]+)
- object_field_set:
object: post
field: phone
# removing last div with phone number
- node_remove: div:nth-child(3)
# concatenate two parts of address with comma+space delimiter
- find:
path: div
do:
- parse
- object_field_set:
object: post
field: address
joinby: ', 'tr:contains('Dates\\Days\\Times') с обязательным эскейпом слешей. Поскольку нужная часть информации находится во вложенной таблице, мы используем еще один переход к нужному элементу по пути 'td:nth-child(2) > table > tbody > tr > td:nth-child(4) > div'. Информация располагается здесь в виде последовательных тегов div,
slice. После чего объединяем оставшиеся теги в один блок командой merge: div. Давайте посмотрим, как это выглядит в логе.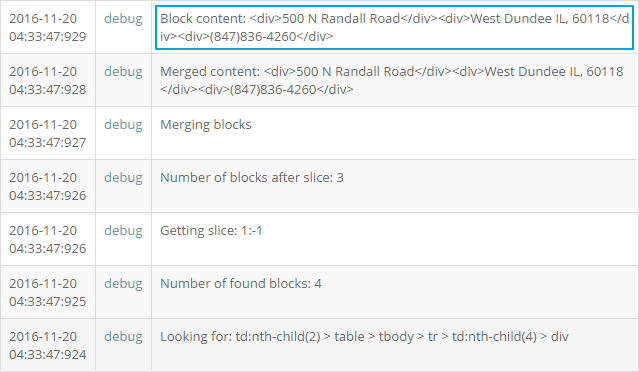

node_remove: div:nth-child(3). Таким образом в блоке у нас останется только адрес, разбитый по двум тегам div.
find с параметром path: div, преобразуем результат в текст командой prase и запишем все это в хранилище в поле address, обязательно указав дополнительный параметр joinby: ', '. Это дает нам возможность объединять записываемые данные в одну строку с разделителем, в нашем случае это запятая с пробелом.
stop и наш сценарий начнет забирать все данные на основной странице, а также данные по каждому Мероприятию, переходя на страницы с деталями, с последующей записью хранилища post в базу данных.Вот и всё :)
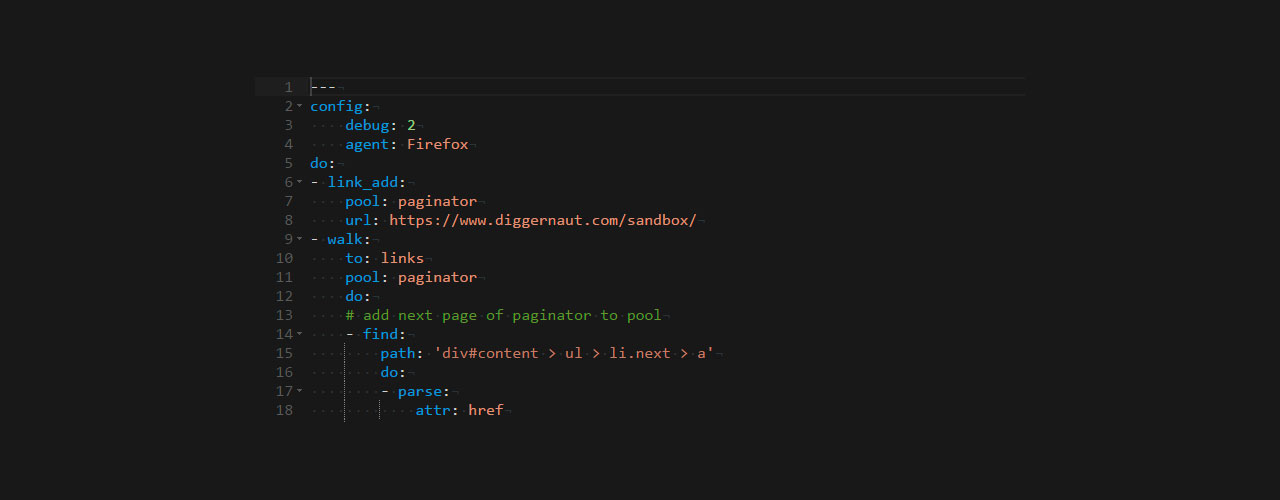
do:
- link_add:
pool: paginator
url: https://www.diggernaut.com/sandbox/
- walk:
to: links
pool: paginator
do:
# add next page of paginator to pool
- find:
path: 'div#content > ul > li.next > a'
do:
- parse:
attr: href
- normalize:
routine: url
- link_add:
pool: paginator
Active,