
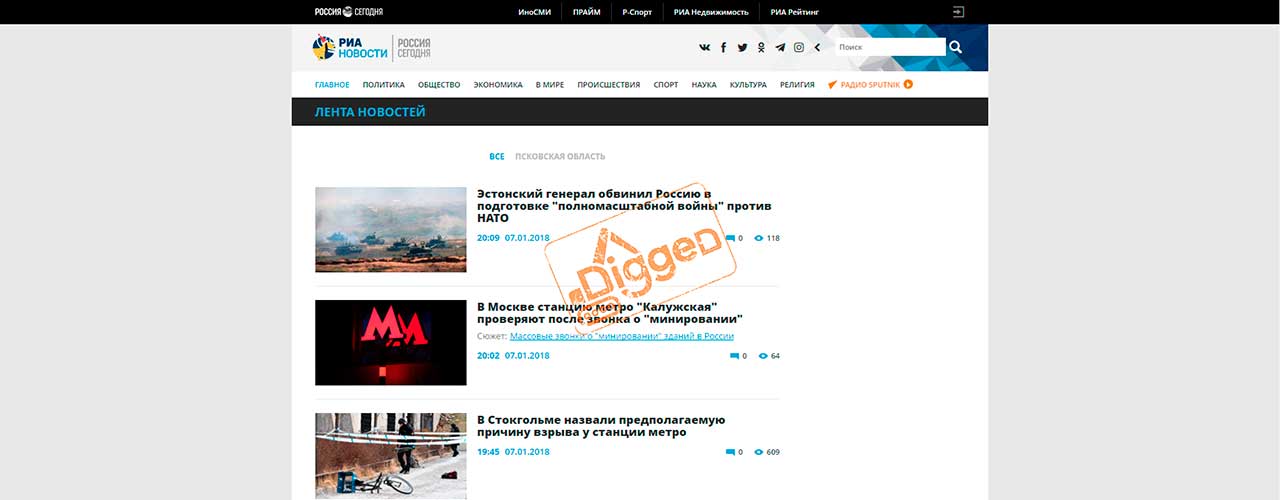
Парсеры новостных сайтов достаточно востребованы, например, если у вас новостой агрегатор, или, к примеру, вам нужно собирать местные новости из различных ресурсов для показа на своем сайте с географическим таргетированием, то вам необходим парсер. Также данные новостных агенств и СМИ часто используются для проведения исследований, машинного обучения и анализа. Распарсить новостую ленту на большинстве ресурсов, как правило, несложно, именно поэтому мы возьмем один из простых сайтов, а именно РИА Новости и научим вас писать парсеры самостоятельно.
Мы будем использовать Google Chrome как наш основной инструмент для работы с сайтом, и для начала мы советуем вам поставить расширение для Google Chrome: Quick Javascript Switcher — оно позволит вам быстро выключать и включать Javascript для сайтов. Это используется для того, чтобы быстро определить как именно данные выводятся на страницу: на стороне сервера или с помошью Javascript (это могут быть данные, внедренные в JS на странице, скрытый блок на странице, который включается JS или же данные забираются дополнительным XHR запросом).
Давайте откроем страницу с лентой https://ria.ru/lenta/ в нашем браузере и отключим JS для сайта с помощью расширения которое мы поставили ранее:
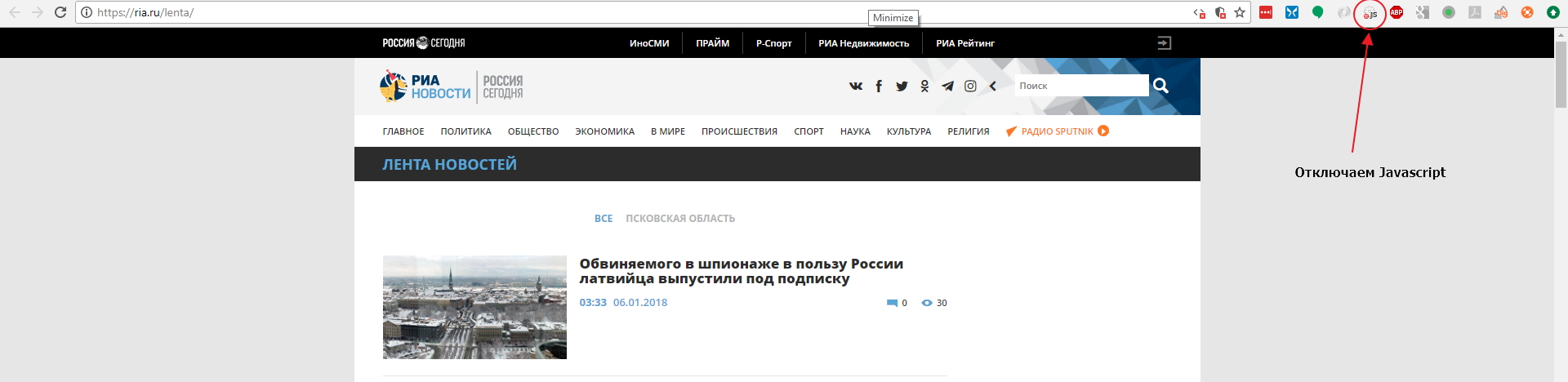
Мы увидим что данные ленты отображаются в браузере. Это означает, что новостная лента формируется на стороне сервера и мы сможем забрать данные просто загрузив страницу в парсер. Однако на странице показано только 20 последних заголовков и что же нам делать если нужно забирать 200 последних? Нам придется изучить механизм работы пагинатора. На разных сайтах пагинаторы работают по разному, поэтому не существует универсального решения и для каждого сайта вам придется разбираться в механизме его работы.
Откроем Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Показать код»:
После этого у вас откроется интерфейс разработчика:
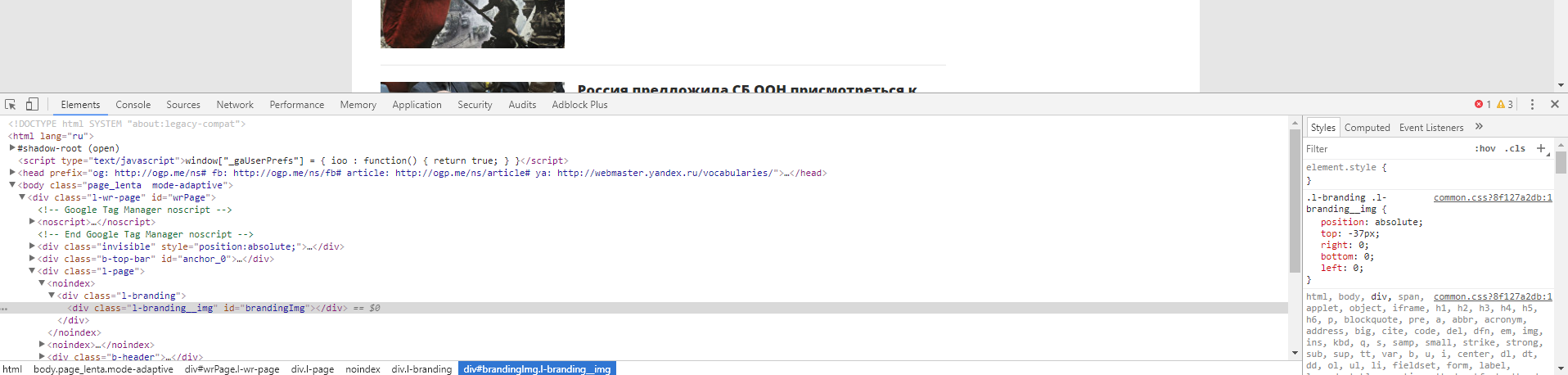
В основном мы будем взаимодействовать с вкладками Elements и Network. Elements — поможет нам работать с DOM структурой, находить элементы страницы, проверять CSS селекторы, искать CSS селекторы и содержимое, и так далее. Во вкладке Network мы можем изучать запросы, которые делает браузер к серверу. Это потребуется нам для нахождения XHR или JS запросов, или же если нам нужно изучить структуру какого-либо запроса (заголовки, куки и тд) для точной имитации его в парсере. Если вы незнакомы с инструментами для разработчика, мы рекомендуем вам посмотреть следующее обзорное видео: Chrome DevTools. Обзор основных возможностей веб-инспектора.
Сейчас нам нужно добраться до конца страницы и найти там пагинатор. Мы видим что здесь он организован как одна кнопка «ЗАГРУЗИТЬ ЕЩЕ», которая подгружает следующие 20 записей используя XHR (Ajax) запрос, то есть если вы кликните на кнопку, ничего не произойдет, поскольку мы выключили Javascript для этого сайта.
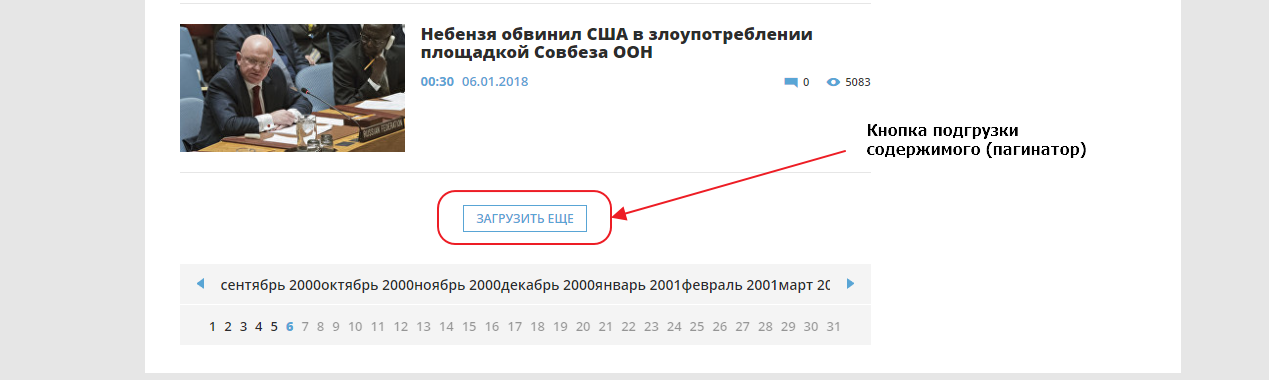
Первым делом найдем эту кнопку в элементах. Для того, чтобы это сделать быстро, можно воспользоваться специальным инструментом для выбора элемента на странице:
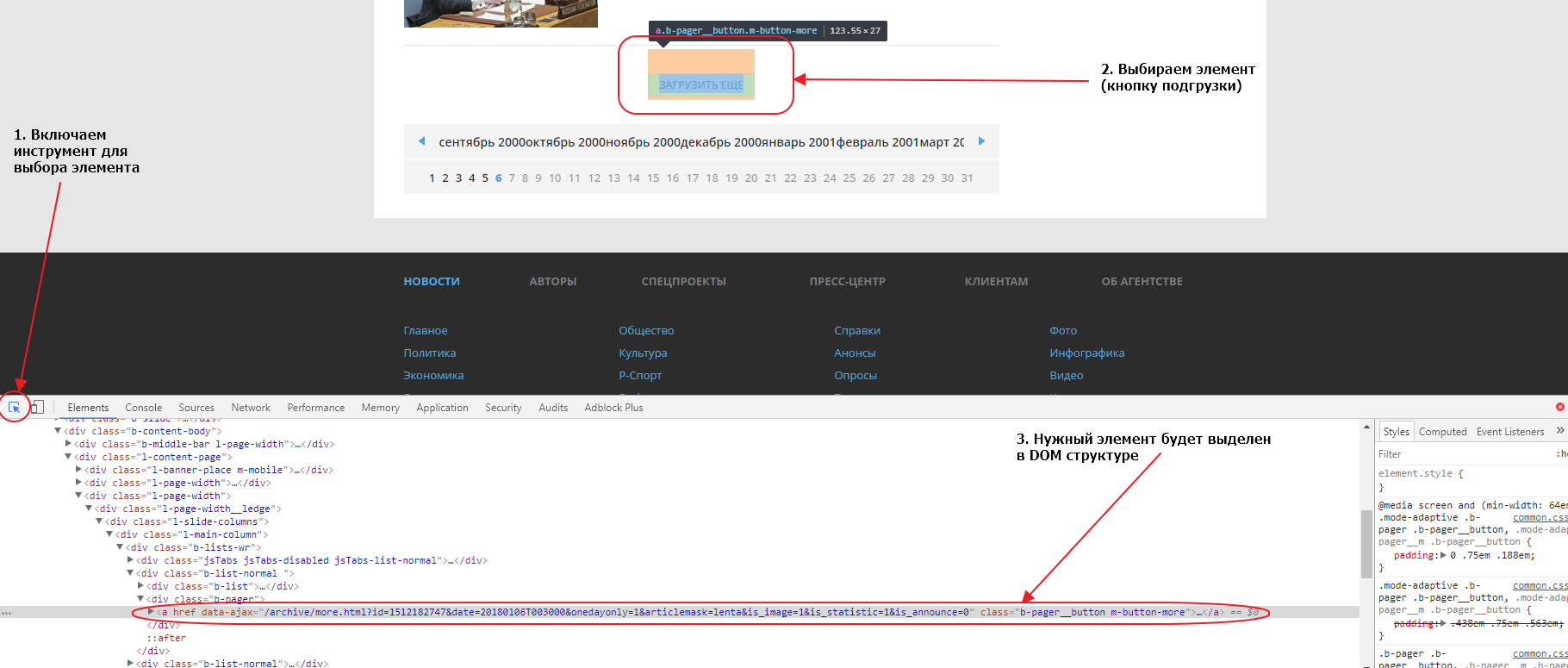
Если мы внимательно посмотрим на элемент, мы увидим что атрибут href у него пустой. Именно поэтому ничего не происходит при нажатии на линк, если отключен Javascript. Однако, мы видим что URL, используемый для подгрузки, указан в атрибуте data-ajax, именно этот URL и используется JS для подгрузки следующих 20 записей при нажатии на кнопку. Так как URL нам известен, нам совершенно не нужно анализировать запросы во вкладке Network. Соответсвенно, чтобы забрать следующие 20 записей, нам нужно забрать парсером этот URL:
https://ria.ru/archive/more.html?id=1512199556&date=20180106T154008&onedayonly=1&articlemask=lenta&is_image=1&is_statistic=1&is_announce=0.
Если загрузить в новой вкладке браузера этот URL мы получим следующие 20 записей и увидим что там тоже есть кнопка для загрузки следующих записей. Теперь нам нужно найти селектор (CSS селектор) для этого элемента. Сделаем это во второй вкладке, в которой у нас загружены вторые 20 записей. Также открываем в этой вкладке инструменты разработчика и выбираем элемент-ссылку «Загрузить еще», так, чтобы элемент выделился в DOM структуре. Теперь нужно кликнуть правой кнопкой мыши на элементе, затем выбрать опцию Copy и следом опцию Copy selector:
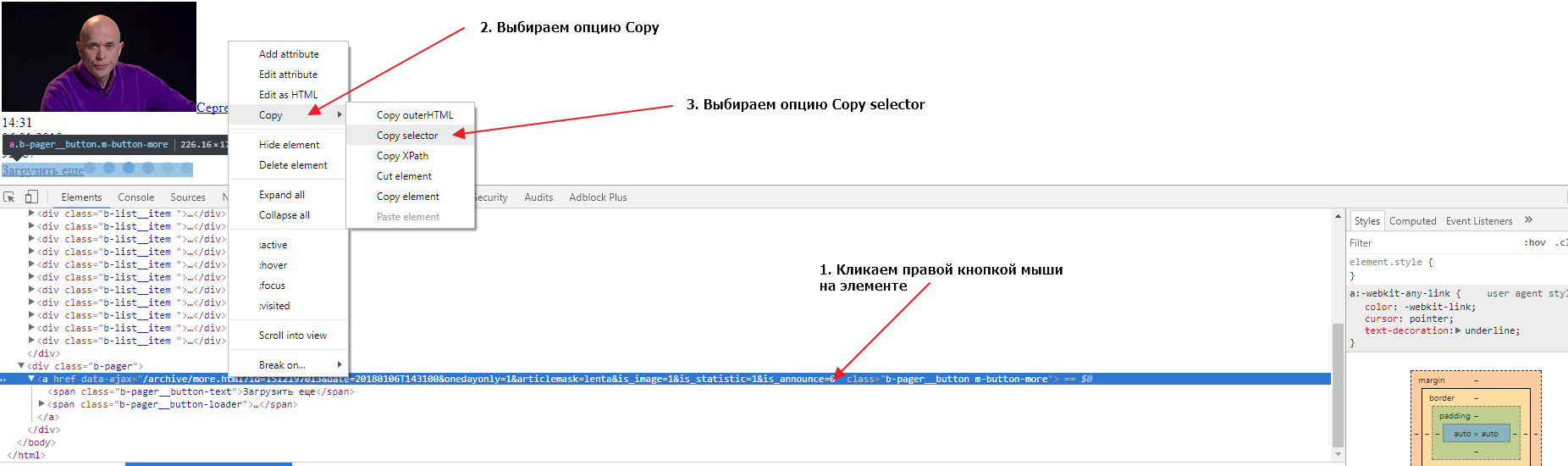
Давайте проверим, выбирает ли наш селектор ровно один элемент во второй и первой вкладке браузера. Для этого нужно в инструментах разработчика сделать активной вкладку Elements, нажать сочетание клавиш CTRL + F и в открывшуюся форму вставить наш селектор:

Мы видим, что селектор выбирает только один элемент, что очень хорошо. Если бы селектор выбирал несколько элементов, нам бы пришлось проверить все выбранные элементы и, либо подкорректировать селектор, так чтобы он выбирал только один элемент, либо в парсере брать срез найденных по селектору элементов, поскольку нам нужен только один элемент.
Тоже самое нужно сделать для другой вкладки, там где у нас открыта начальная страница. Сделать это нужно, чтобы удостовериться, что селекторы одинаковые на основной странице и на странице подгрузки. Иметь одну логику работы всегда лучше чем несколько, поэтому принцип унификации очень важен, в том числе и для подбора CSS селекторов. Если мы попробуем поискать наш селектор, мы обнаружим, что ничего не найдено. Дело в том, что элемент div.b-pager > a не находится в руте ноды body. Если мы уберем из пути body > и оставим только div.b-pager > a, то наш элемент будет найден в обеих вкладках и только один раз.
Мы определили, что для организации подгрузки данных в парсере, после загрузки страницы, мы должны найти элемент div.b-pager > a, забрать содержимое атрибута data-ajax и пройти по этому URL. Поскольку на страницах с подгрузкой структура элементов такая же, мы можем использовать единый логический блок. А для организации переходов по страницам мы можем использовать пул линков. Изначально мы поместим в пул только первый URL https://ria.ru/lenta/ и затем на каждой итерации мы будем добавлять в пул новый URL, который мы будем извлекать с загруженной страницы. Так мы организуем пагинацию в нашем парсере.
Теперь нам нужно определить как нам забирать новости со страниц, для этого нам нужно найти главный элемент блока в который обернута каждая новость. Сделать это мы можем точно так же, как мы делали это для кнопки подгрузки данных:
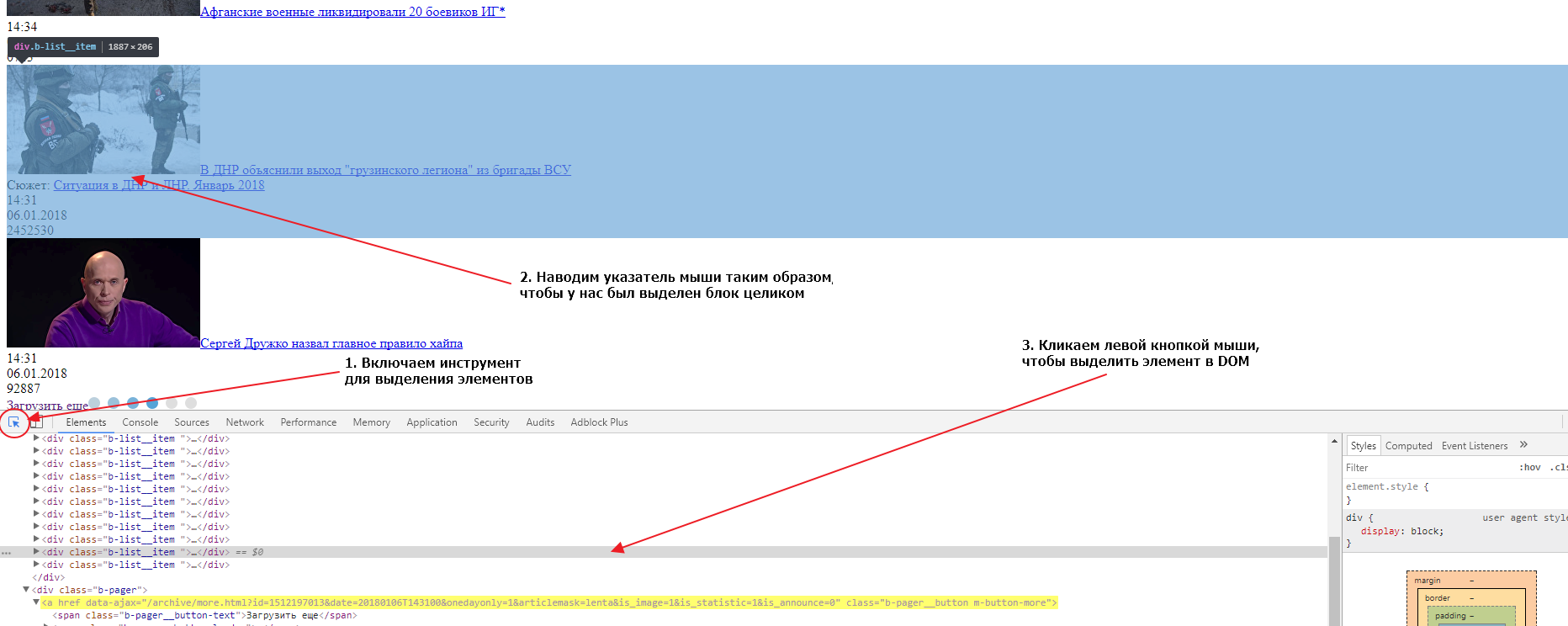
Если вы внимательно посмотрите на DOM структуру, вы увидите, что каждая новость обернута в элемент div с классом b-list__item. Таких элементов на странице ровно 20. Это и есть элемент, который нам нужен и CSS селектор для него будет div.b-list__item. Давайте сейчас проверим, насколько верно мы определили селектор для обеих вкладок (страницы с подгрузкой и основной страницы). Делаем мы это так же как мы проверяли валидность селектора для кнопки подгрузки. На обеих страницах селектор найдет по 20 элементов, значит наш селектор верен и мы можем его использовать.
Наш парсер на каждой странице должен находить этот селектор, и затем для каждого найденного элемента создавать новый объект данных, проходить в дочерние элементы, извлекать данные и записывать их в поля этого объекта данных, записывать объект данных в базу данных.
Давайте откроем один из элементов. Посмотрим какие у него есть дочерние элементы и какие данные нам нужны:

URL до страницы с новостью — находится просто в теге a, у этого тега нет класса или других атрибутов, кроме href. Поэтому единственный селектор, который мы можем использовать — a. Обратите внимание, что селекторы мы строим относительно родительского блока, поскольку мы в нем находимся, а не относительно всей страницы. Однако при таком селекторе если в блоке новости друг окажется еще один тег a в наших данных будет записан только последний, а нам нужен первый, поэтому мы можем брать срез элементов (элемент с номером 0) или же мы можем проверять в нашем a наличие дочернего элемента span с классом b-list__item-title. В последнем случае наш селектор будет выглядеть как a:haschild(span.b-list__item-title).
Изображение — нам нужно забрать URL до зображения, который находится в атрибуте src тега img. У этого тега есть атрибут itemprop=»associatedMedia», который выглядит достаточно надежным признаком для выборки нужного тега img. Поэтому мы можем использовать его в CSS селекторе: img[itemprop=»associatedMedia»].
Заголовок — здесь нет никаких подводных камней, наш заголовок находится в элементе span с классом b-list__item-title, поэтому CSS селектор будет таким: span.b-list__item-title.
Время и Дата — так же просто как и заголовок, получаем селекторы div.b-list__item-time и div.b-list__item-date соответственно.
Количество комментариев и Количество просмотров — находятся в элементах span с классом b-statistic__number, то так как в текущем блоке по такому селектору будут найдены оба элемента, то мы можем либо использовать срезы для выбора определенного элемента, либо использовать родительский элемент как часть селектора. В первом случае родительский элемент — это тег span с классом m-comments, и наш селектор получается таким span.m-comments > span.b-statistic__number. Во втором случае, родительский тег span с классом m-views формирует CSS селектор: span.m-views > span.b-statistic__number.
Вот мы и определили все селекторы для выбора полей которые нам надо собрать. Также давайте ограничим количество забираемых новостей, сделаем так чтобы парсер забирал 200 первых новостей (или 10 страниц). Мы можем организовать это с помощью счетчика, будем считать количество загруженных страниц и если счетчик примет значение более 9, просто не будем добавлять новый линк в пул. Займемся теперь написанием конфигурации парсера:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Устанавливаем счетчик страниц равным 1
- counter_set:
name: pages
value: 1
# Добавляем начальный URL в пул
- link_add:
url:
- https://ria.ru/lenta/
# Начинаем итерацию по пулу с последовательной загрузкой страниц из пула
- walk:
to: links
do:
# Делаем паузу 2 секунды для уменьшения нагрузки на сервер источника
- sleep: 2
# Находим кнопку подгрузки
- find:
path: div.b-pager > a
do:
# Считываем в регистр значение счетчика pages
- counter_get: pages
# проверяем если значение регистра больше 9
- if:
type: int
gt: 9
else:
# если значение меньше 9 - парсим значение аттрибута data-ajax текущего элемента в регистр
- parse:
attr: data-ajax
# делаем нормализацию значения в регистре, убираем лишние пробелы, унифицируем пробельные символы в ASCII пробелы
- space_dedupe
# удаляем все ведущие и завершающие пробелы значения в регистре, если они есть
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: \w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и добавляем линк в пул
- normalize:
routine: url
- link_add
# Находим все блоки с новостями и начинаем итерировать по найденным элементам
- find:
path: div.b-list__item
do:
# создаем новый объект данных с именем item
- object_new: item
# находим элемент с URL к странице с новостью
- find:
path: a:haschild(span.b-list__item-title)
do:
# парсим значение атрибута href в регистр
- parse:
attr: href
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: \w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле url объекта item
- normalize:
routine: url
- object_field_set:
object: item
field: url
# находим элемент с заголовком новости
- find:
path: span.b-list__item-title
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле headline объекта item
- object_field_set:
object: item
field: headline
# находим элемент с изображением
- find:
path: img[itemprop="associatedMedia"]
do:
# парсим значение атрибута src текущего элемента в регистр
- parse:
attr: src
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: \w+
do:
- normalize:
routine: url
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле image объекта item
- object_field_set:
object: item
field: image
# находим элемент с временем
- find:
path: div.b-list__item-time
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле time объекта item
- object_field_set:
object: item
field: time
# находим элемент с датой
- find:
path: div.b-list__item-date
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле date объекта item
- object_field_set:
object: item
field: date
# находим элемент с количеством комментариев
- find:
path: span.m-comments > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле comments объекта item
- object_field_set:
object: item
field: comments
# находим элемент с количеством просмотров
- find:
path: span.m-views > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле views объекта item
- object_field_set:
object: item
field: views
# сохраняем объект данных item в базу данных
- object_save:
name: item
# увеличиваем значение счетчика pages на 1
- counter_increment:
name: pages
by: 1Вам осталось создать новый диггер на платформе Diggernaut, перенести в него этот сценарий и запустить. Надеемся что этот материал был полезен и помог вам в изучении нашего мета-языка.
Удачного парсинга!
спасибо за мануал…
Зачем брать 200 новостй.. Тем более там должна быть rss. Не?
Для анализа например. У РИА есть рабочий RSS? Поделитесь!.. Кстати rss тоже можно без проблем парсить, но когда парсить нужно один раз и получить сразу много данных — этот вариант не подходит.
Количество можно менять, 200 было взято как цифра с потолка. Целью статьи было дать реальный пример парсинга новостей тем, кто осваивает наш мета-язык.
А RSS парсить неинтересно 🙂 Он же стандартизирован.