
Если вы просто ищете парсер Amazon и не хотите освоить мастерство написания парсеров, вы можете просто загрузить готовый парсер под нужный маркет Amazon напрямую в ваш аккаунт Diggernaut из нашего каталога парсеров:
Парсер Amazon.com
Парсер Amazon.co.uk
Парсер Amazon.de
Парсер Amazon.fr
Парсер Amazon.it
Парсер Amazon.in
Парсер Amazon.ca
Парсер Amazon.es
Парсер Amazon.co.jp
Сегодня мы напишем парсер для Amazon.com. Парсер будет предназначен для забора базовой информации о товарах из определенной категории. При желании вы сможете самостоятельно расширить набор забираемых данных. Или, если вы не хотите тратить свое время, у вас есть возможность нанять наших разработчиков.
Важные моменты перед началом разработки
Амазон отдает товары с привязкой к гео-фактору, который определяется по IP адресу клиента. Поэтому, если вас интересует информация для рынка США, вы должны использовать прокси из США. В нашей платформе Diggernaut вы можете указать гео-привязку к определенной стране с помощью опции geo. Однако, это работает только на платных планах. На бесплатных вы можете использовать ваши собственные прокси сервера. Как именно их использовать рассказано в нашей документации в ссылке выше. Если вам не нужно четкое таргетирование по стране, можно не указывать никаких настроек в прокси секции. В этом случае будут использоваться прокси из нашего пула из разных стран. Конечно, если вы запускаете парсер в облаке. Для уменьшения шанса блокировки мы также будем использовать паузы между запросами.
Есть еще один момент о котором мы хотим вам рассказать. Амазон может временно заблокировать IP с которого идут автоматизированные запросы. Для этого могут использоваться разные средства. Например, Амазон может показать капчу, или же показать страницу с ошибкой. Поэтому, для успешного функционирования парсера мы должны продумать как парсер будет ловить и обходить эти случаи.
Обходим капчу Amazon.com
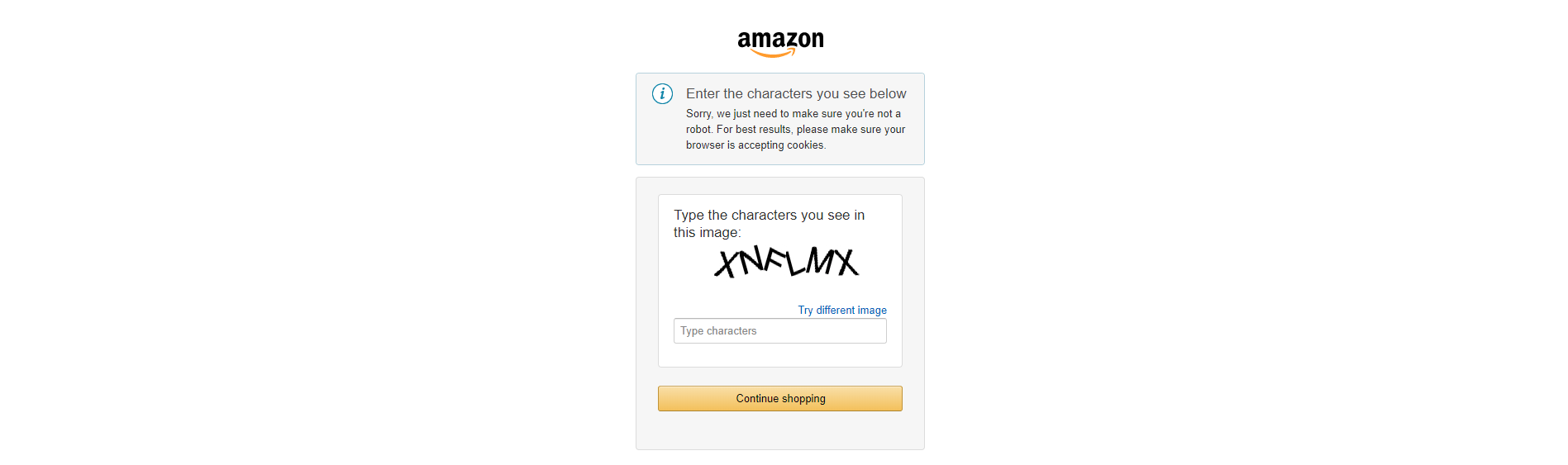
Капчу мы будем обходить с помощью нашего внутреннего решения для капчи. Так как этот механизм работает как микросервис, он доступен только при запуске парсера в облаке, зато он абсолютно бесплатен для всех пользователей платформы Diggernaut. Если вы хотите запускать скомпилированный парсер у себя, вы должны будете использовать один из интегрированных сервисов для решения капчи: Anti-captcha или RuCaptcha. Вам также понадобится собственный аккаунт в одном из этих сервисов. Кроме этого вам придется немного изменить код парсера. А именно, настроить параметры команды captcha_resolve.
Обходим ошибку доступа
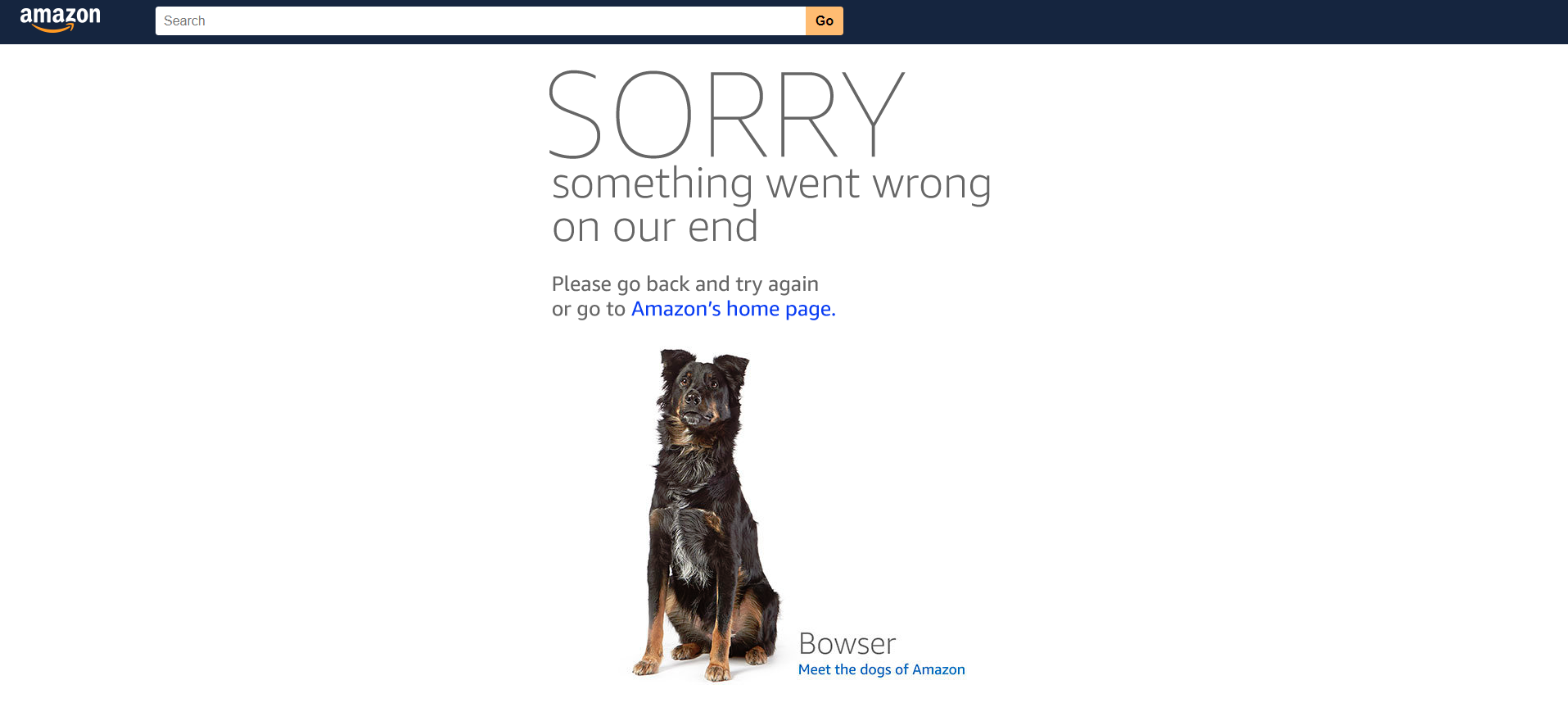
Для обхода ошибки доступа мы будем использовать ротацию прокси и режим repeat для команды walk. Этот режим позволяет зацикливать запрос страницы до момента пока мы не укажем, что все прошло хорошо. При ротации прокси, парсер выбирает следующий прокси из списка. Если список заканчивается, парсер возвращается обратно к первому прокси. Эта функция работает как с прокси, указанными в парсере пользователем, так и с прокси в нашем облаке, доступ к которым имеют все пользователи платформы Diggernaut.
Алгоритм работы парсера Amazon
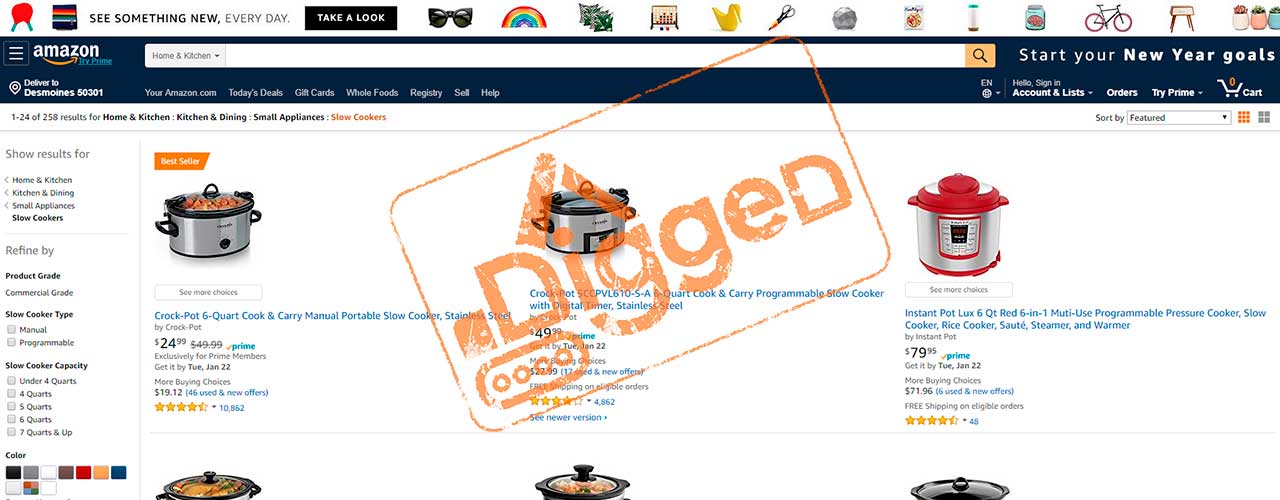
Поскольку в категории будет пагинатор и много страниц с товарами, мы будем использовать пул. Это позволит нам описать логику парсинга только один раз, для всего пула, а не для каждой страницы в отдельности. Примите во внимание, что максимальное количество страниц в одной категории (или поисковом запросе), отдаваемых Амазоном, 400. Поэтому, если в вашей категории более 8000 товаров, и вы хотите собрать максимальное количество, то вам нужно пересмотреть параметры поискового запроса, или вы должны будете забирать товары из подкатегорий. Наш парсер сможет забирать товар по любому поисковому запросу, поэтому вы сможете в браузере настроить все фильтры запроса и использовать URL из адресной строки браузера как стартовую страницу для парсера.
Алгоритм будет следующим. Мы создадим пул и положим в него стартовую страницу. Пройдем в пул, загрузим очередную страницу из пула. Проверим есть ли на странице капча, если есть решим ее и перегрузим страницу. Также проверим, не вернул ли Амазон ошибку доступа, если вернул — сменим прокси и перегрузим страницу. Если все проверки прошли успешно, то парсим страницу и забираем товары. Находим пагинатор, извлекаем линк на следующую страницу и вносим ее в пул.
Давайте посмотрим на стартовую страницу и определим селекторы, которые нам понадобятся для нахождения пагинатора, блока с товаром и извлекаемых полей. Для этого нам понадобится Google Chrome и встроенные в него инструменты для разработчика.
Находим CSS селектор для листингов (товаров)
Откроем в браузере следующий URL:https://www.amazon.com/s?bbn=16225011011&rh=n%3A%2116225011011%2Cn%3A284507%2Cn%3A289913%2Cn%3A289940&dc&fst=as%3Aoff&ie=UTF8&qid=1547931533&rnid=289913&ref=sr_nr_n_1
Нажмем на странице правую кнопку мыши и выберем опцию «Показать код».
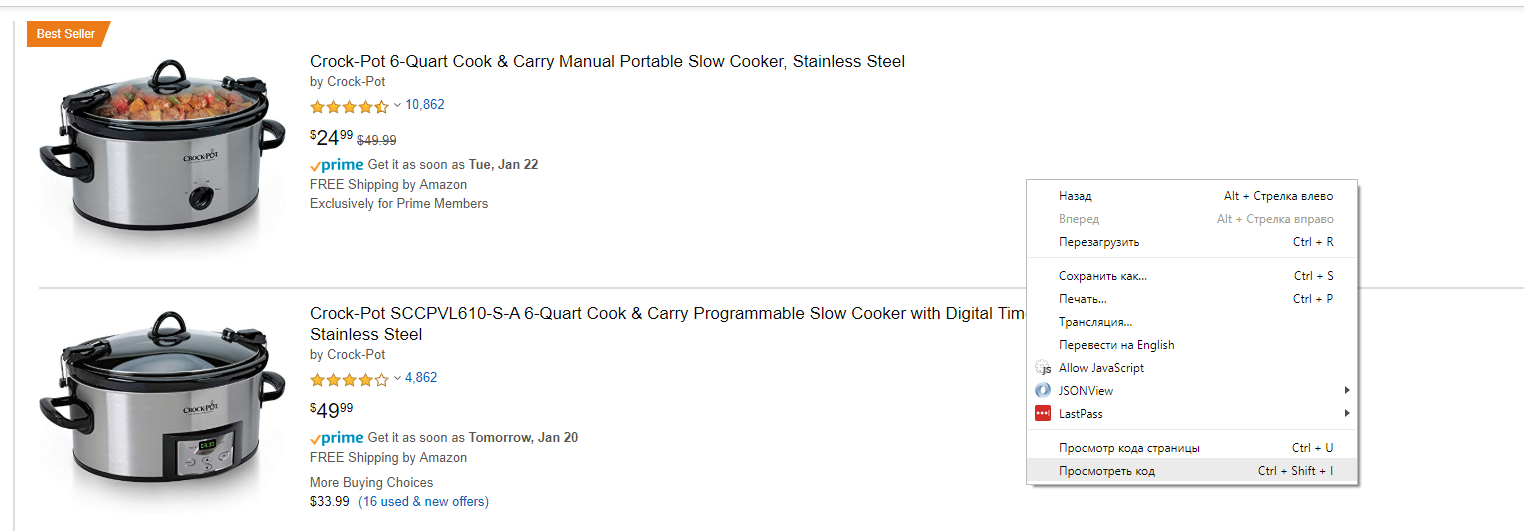
Это откроет панель с инструментами разработчика. Нас интересует инструмент для выбора элемента на странице. Поэтому активируем этот инструмент и выберем на странице первый блок с товаром. В окошке с исходным кодом страницы вы сразу увидите выбранный элемент.
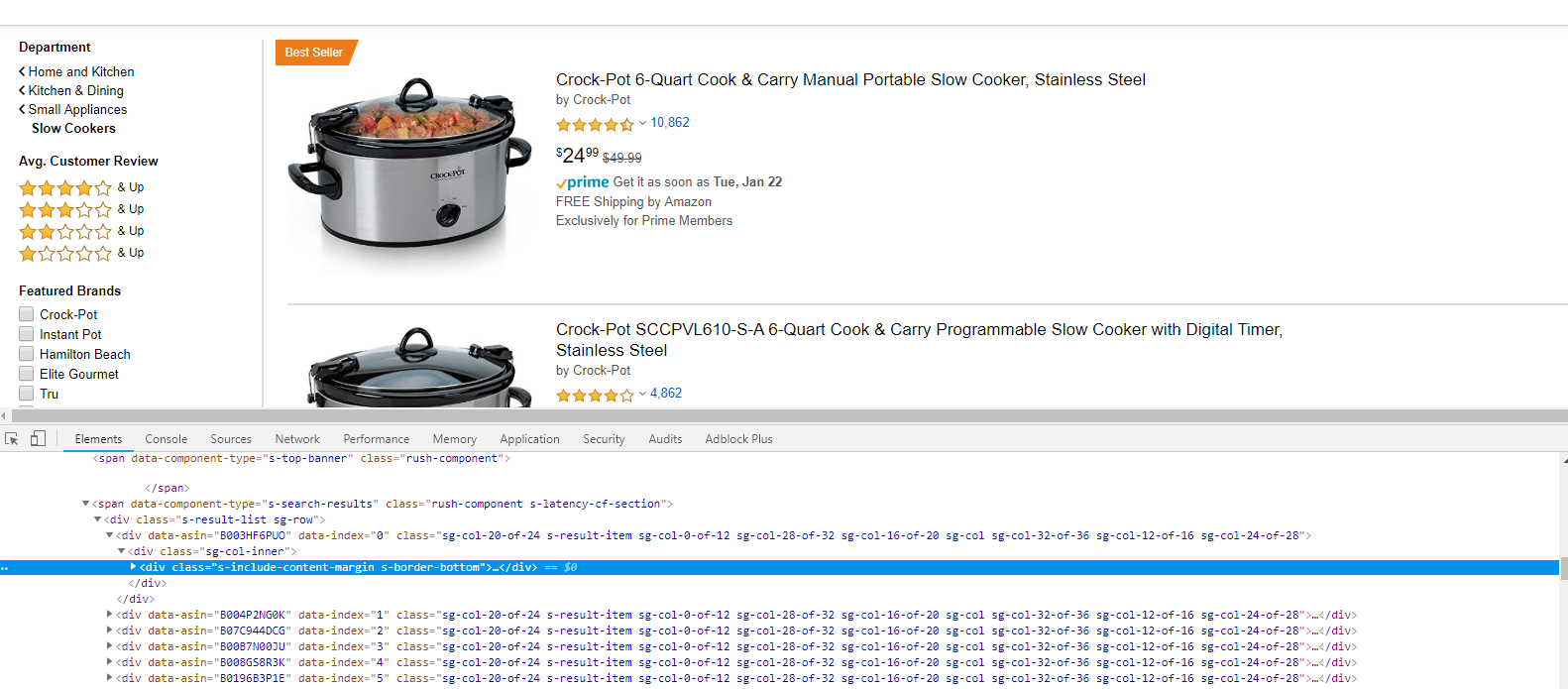
Если внимательно посмотреть на HTML код в этой части, то будет видно, что все листинги имеют класс s-result-item. Поэтому нашим селектором для листингов будет: div.s-result-item.
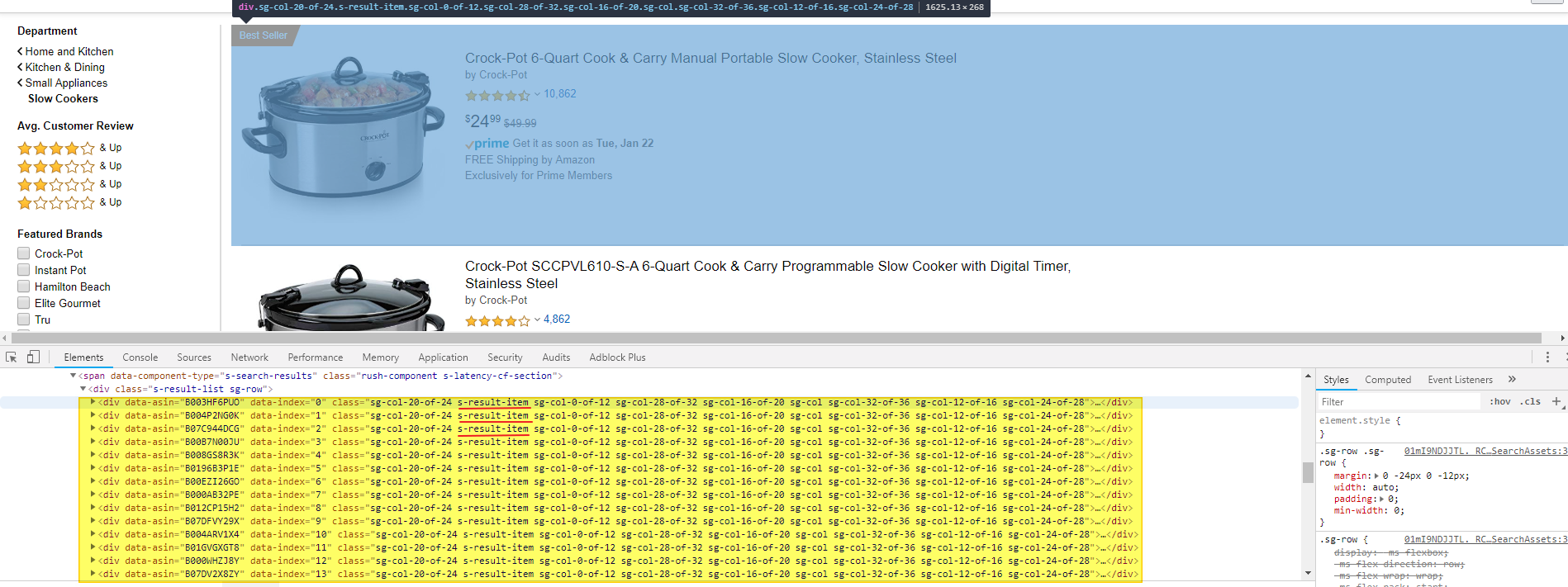
Находим пагинатор и определяем CSS селектор для ссылки на следующую страницу
Пагинатор находится внизу страницы.
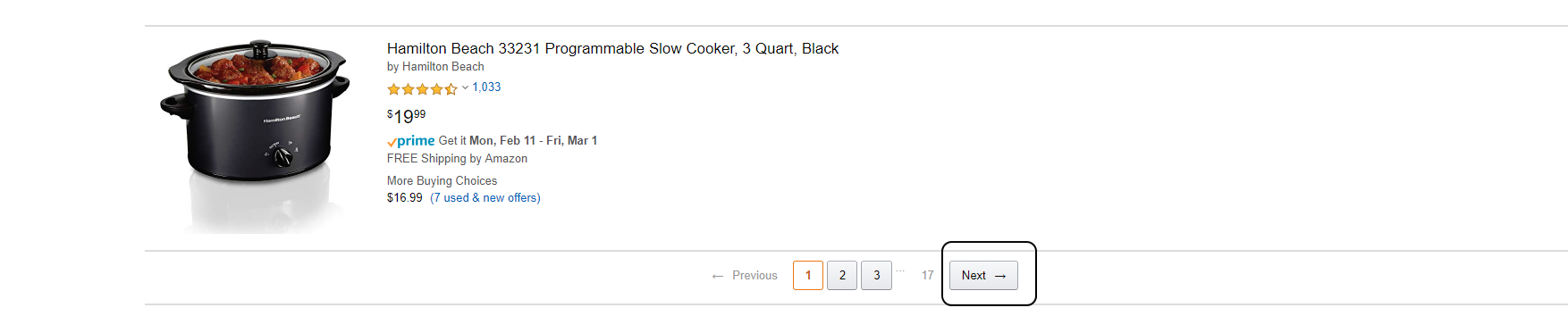
По аналогии с поиском листингов, откроем инструменты разработчика и выберем кнопку «Next». В исходном HTML коде страницы мы увидим выбранный элемент. Это тег a внутри тега li с классом a-last. Поэтому наш селектор будет таким: li.a-last > a
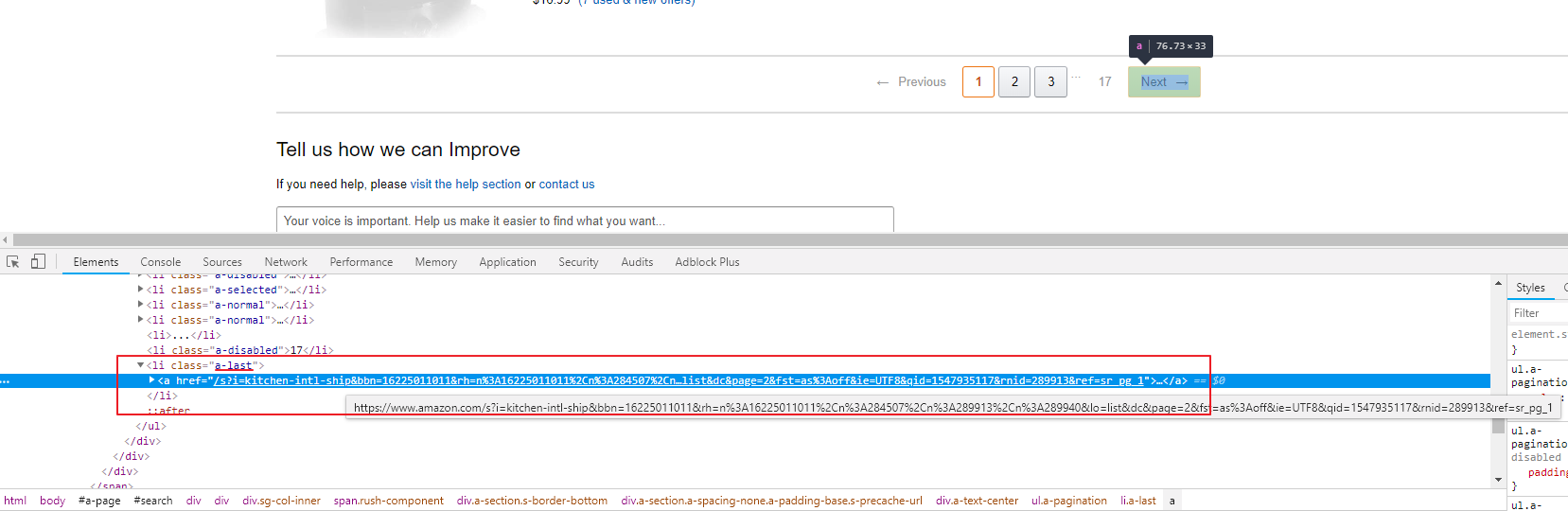
Теперь у нас есть селекторы для листингов и следующей страницы в каталоге. Приступим к извлечению селекторов для полей листинга (товара).
Селекторы для полей листинга

Искать селекторы мы будем на любом из товаров. Алгоритм точно такой же как и при получении любых других селекторов: мы выбираем инструмент для выбора элемента и выбираем его на странице, смотрим и изучаем фрагмент HTML и получаем селектор. Но сначала давайте внимательно посмотрим на элемент с листингом: div.s-result-item. В этом теге есть аттрибут data-asin. Там хранится ASIN (уникальный идентификатор вариации товара в Amazon). Имея этот ASIN можно легко зайти на страницу товара, поскольку он может быть сформирован используя следующий темплейт: https://www.amazon.com/dp/<%ASIN%>, где — ASIN товара в Амазон. Таким же образом может быть сформирован линк на страницу с предложениями от других продавцов на Амазон: https://www.amazon.com/gp/offer-listing/<%ASIN%>. Поэтому мы просто обязаны собрать его в поле. Селектор для него не нужен поскольку он совпадает с селектором листинга. То есть, когда мы войдем в листинг, нам нужно будет просто спарсить аттрибут data-asin текущего блока.
Название товара — h5, в блоке листинга только один элемент h5, поэтому можно смело использовать этот селектор
Бренд — бренд выбрать не так просто как название, потому что все классы в блоке листинга генерализированы и у блока с брендом нет уникального класса или id. Поэтому нам нужно найти какую-то привязку. Мы знаем что у нас в листинге только один h5 и что блок с брендом находится в одном родительском блоке с h5. Это значит, что мы можем выбрать родительский блок, используя директиву haschild. Эта директива означает что нужно выбрать элемент у которого есть прямой дочерний элемент, указанный в селекторе. В данном случае селектор для родительского блока будет таким: div.a-section:haschild(h5). Теперь мы лишь должны добавить селектор для блока с брендом относительно родительского блока: div.a-color-secondary. В результате мы получаем следующий селектор: div.a-section:haschild(h5) > div.a-color-secondary. Также мы видим что в блоке бренд указан с приставкой «by». Поэтому мы должны будем почистить данные перед записью в объект, используя функцию нормализации.
Рейтинг и количество отзывов — мы видим, что рейтинг и количество отзывов находятся в тегах span. И то, что у этих тегов есть аттрибут aria-label. Чтобы выбрать все элементы с этим аттрибутом, мы можем использовать такой селектор: span[aria-label]. Однако таких элементов может быть 2, 3, 4 или даже 5 в одном листинге. Как быть в таком случае? На помощь нам придет опция slice для команды find. Таким образом мы сможем отобрать только первый найденный элемент (рейтинг) и второй (количество отзывов). Также для обоих полей мы будем парсить содержимое аттрибута aria-label. Но как вы видите, значения в этих полях содержат лишний текст и символы, а мы хотим получить числовые значения в нашем объекте с данными. Если мы используем типы int и float при записи поля объекта, то при экспорте датасета в Excel у вас будут корректно работать цифровые фильтры и сортировка. Кроме того, используя валидационную схему для датасета, можно отфильтровывать ненужные записи по числовому значению, используя числовые фильтры. Поэтому, для парсинга числовых значений мы будем использовать опцию filter команды parse.
Цена — тут все просто, цена находится в теге span с классом a-price. В этом элементе цена представлена в разном написании, проще будет ее забрать из элемента: span.a-price > span.a-offscreen. Однако на некоторых листингах может быть 2 цены, если товар продается со скидкой. Поэтому мы будем использовать опцию slice и выбирать первый из найденных элементов (элемент с индексом 0, поскольку нумерация элементов массива начинается с 0).
Prime — иконка, показываающая есть ли у товара бесплатная экспресс-доставка в рамках Amazon Prime подписки. Селектор для этого элемента тоже простой, поскольку у этой иконки есть уникальный класс: i.a-icon-prime. Работать это будет следующим образом. Мы будем записывать значение по умолчанию («No») в поле prime. Затем будем искать блок с иконкой и проходить в него и записывать «Yes» в поле prime. Если иконка будет в листинге, парсер пройдет в этот блок и выполнит указанные команды. Если нет, то в поле останется значение по умолчанию.
Количество продавцов — нас не интересуют продавцы б/у вещей, поэтому мы соберем только те цифры где указано «new offers». Это будут конечно не совсем точные данные, потому что иногда там указываются новые и бывшие в употреблении вещи. Для более точной картины по этому вопросу нужно парсить страницу с предложениями от других продавцов. В данном случае мы ограничимся тем, что есть на этой странице. Селектор для линка: a. Однако в блоке с листингом может быть более одного линка, причем разное количество. Поэтому мы будем использовать директиву contains, которая означает, что в селекторе должен содержаться указанный текст. Наш селектор будет таким: a:contains("new offers").
Ссылка на полноразмерное изображение — селектор для изображения будет очень простой: img.s-image. Однако, изображение в аттрибуте src не полноразмерное. Как же быть? Откроем вам маленький секрет. Чтобы из урезанного изображения в Amazon сделать полноразмерное, нужно всего ли удалить часть URL. Допустим, в аттрибуте src мы имеем следующий URL:https://m.media-amazon.com/images/I/81pMpXtqWrL._AC_UL436_.jpg. Все что нам нужно сделать — это удалить блок _AC_UL436_ между точками перед расширением файла и убрать одну из двух точек. Это мы сделаем используя функцию нормализации.
Каталог с другой компоновкой
Иногда Амазон отдает каталог используя совершенно другой темплейт. Этот темплейт имеет совершенно другие селекторы. От чего зависит выбор того или другого темплейта мы не знаем, но у нас есть возможность включить в парсер логику для множества темплейтов. Мы не будем углубляться в детали забора селекторов, просто перечислим их ниже.
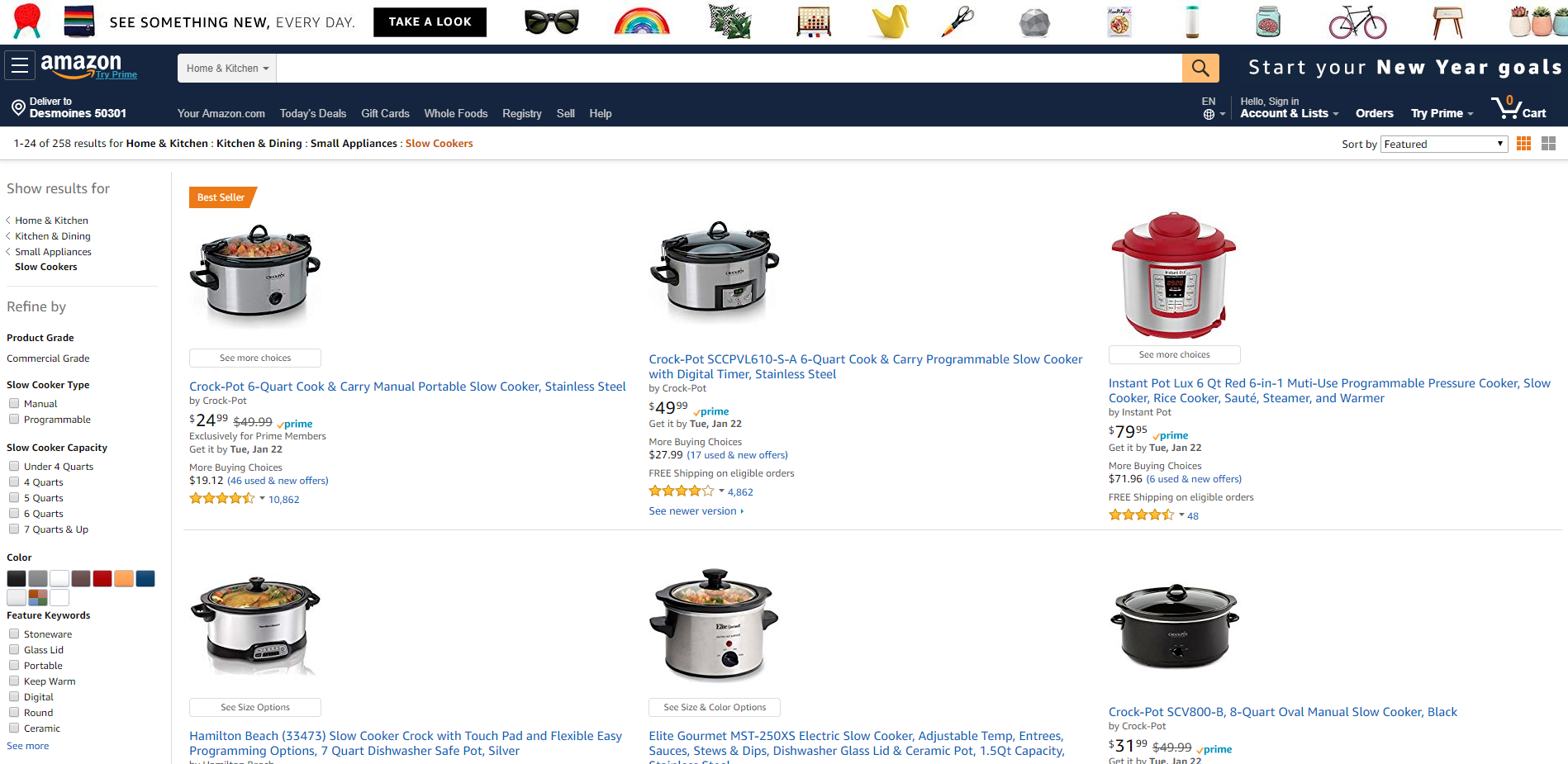
Селектор листингов: li.s-result-item
Селектор следующей страницы: a.pagnNext
Название товара: h2
Бренд: div.a-spacing-mini:has(h2) > div.a-row > span (используем slice и выбираем последний найденный элемент)
Рейтинг: i.a-icon-star>span
Количество отзывов: div.a-spacing-none:has(i.a-icon-star) > a.a-size-small
Цена: span.a-offscreen
Prime: i.a-icon-prime
Количество продавцов: a:contains("new offers")
Ссылка на полноразмерную картинку: img.s-access-image
Теперь у нас есть все необходимые селекторы и план обработки сырых данных. Приступим к написанию конфигурации парсера.
Пишем парсер Amazon
Входите в ваш аккаунт на платформе Diggernaut, создайте новый диггер в любом вашем проекте и нажмите на кнопку «Добавить конфиг». Далее просто пишите вместе с нами, внимательно читая комментарии.
---
config:
debug: 2
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
do:
# Добавляем в пул стартовый URL (можно добавить целый список)
- link_add:
url:
- https://www.amazon.com/s?bbn=16225011011&rh=n%3A%2116225011011%2Cn%3A284507%2Cn%3A289913%2Cn%3A289940&dc&fst=as%3Aoff&ie=UTF8&qid=1547931533&rnid=289913&ref=sr_nr_n_1
# Устанавливаем переменную в значение "yes" для использования в режиме repeat
# пока значение переменной "yes" команда walk будет перезагружать текущую страницу в пуле
- variable_set:
field: rip
value: "yes"
# Начинаем итерацию по линкам в пуле
- walk:
to: links
repeat_in_pool: <%rip%>
do:
# Ожидаем худшее и включаем repeat
- variable_set:
field: rip
value: "yes"
# Заходим в блок тега title для проверки на ошибку доступа
- find:
path: title
do:
# Парсим текстовое значение текущего блока в регистр
- parse
# Проверяем есть ли слово Sorry в заголовке страницы
- if:
match: Sorry
do:
# Если есть - у нас ошибка доступа. Переключаем прокси.
- proxy_switch
else:
# Если нет, с доступом все в порядке. Начинаем проверку на наличие капчи.
# Заходим в блок body. Обратите внимание на опцию in.
# Так как в данный момент мы находимся в блоке title и в нем конечно же нет тега body
# искать блок мы должны во всем документе, а не в текущем блоке
# для этого используется опция in: doc
- find:
path: body
in: doc
do:
# Парсим текстовое значение текущего блока в регистр (все что у нас есть в теге body - вся страница)
- parse
# Проверяем есть ли заданный текст на странице
- if:
match: Type the characters you see in this image
do:
# Если текст есть - у нас на странице капча и нам надо ее решать
# для этого читаем значения на странице, которые нам нужно будет передать
- find:
path: input[name="amzn"]
do:
- parse:
attr: value
- normalize:
routine: urlencode
- variable_set: amzn
- find:
path: input[name="amzn-r"]
do:
- parse:
attr: value
- normalize:
routine: urlencode
- variable_set: amznr
# Идем в блок с изображением капчи
- find:
path: div.a-row>img
do:
# Парсим URL к изображению
- parse:
attr: src
# Загружаем изображение
- walk:
to: value
do:
# В этом блоке у нас будет изображение закодированное в base64 формат
# Именно так Diggernaut работает с бинарными данными
# Файл кодируется в base64 и с ним можно работать
# используя различный функционал Diggernaut (OCR, сохранение файлов и др)
- find:
path: imgbase64
do:
# Парсим содержимое блока
- parse
# и записываем его в переменную capimg
- variable_set: capimg
# Используем команду для решения капчи
# Указываем diggernaut как провайдера для использования внутреннего механизма.
# Тип капчи у нас amazon
# И сюда же мы передаем изображение, используя переменную capimg
- captcha_resolve:
provider: diggernaut
type: amazon
image: <%capimg%>
# после выполнения команды captcha_resolve мы должны будем иметь
# распознанный текст капчи в переменной captcha
# поэтому читаем значение переменной в регистр
- variable_get: captcha
# И проверяем, если ли там какое-либо значение
- if:
match: \S+
do:
# Если значение есть, отправляем решенную капчу на сервер Amazon
- walk:
to: https://www.amazon.com/errors/validateCaptcha?amzn=<%amzn%>&amzn-r=<%amznr%>&field-keywords=<%captcha%>
do:
else:
# Искомого текста нет, а значит у нас нет капчи
# и мы имеем дело с обычной страницей каталога
# Отключаем режим repeat для этой страницы
- variable_set:
field: rip
value: "no"
# Делаем паузу в 5 секунд
- sleep: 5
# Начнем парсинг
# Сначала соберем следующую страницу и положим ее в пул
- find:
path: li.a-last > a, a.pagnNext
do:
# Парсим аттрибут href
- parse:
attr: href
# Проверяем, есть ли какое либо значение в регистре
- if:
match: \w+
do:
# Если есть, кладем URL в пул
- link_add
# Собираем листинги, заходим в каждый листинг
# Первый темплейт
- find:
path: div.s-result-item
do:
# Парсим аттрибут data-asin чтобы получить ASIN продукта
- parse:
attr: data-asin
# Проверяем наличие ASIN в регистре
- if:
match: \w+
do:
# Создаем новый объект данных
- object_new: item
- object_field_set:
object: item
field: asin
# Давайте тогда сгенерируем URL на страницу продукта
# Сохраняем ASIN в переменной
- variable_set: asin
# Пишем в регистр значение и записываем URL в объект
- register_set: https://www.amazon.com/dp/<%asin%>
- object_field_set:
object: item
field: url
# Собираем имя продукта
- find:
path: h5
do:
- parse
# Нормализуем пробелы
- space_dedupe
# Отрезаем пробелы с конца и начала
- trim
- object_field_set:
object: item
field: title
# Собираем бренд
- find:
path: div.a-section:haschild(h5) > div.a-color-secondary
do:
- parse
# Нормализуем пробелы
- space_dedupe
# Отрезаем пробелы с конца и начала
- trim
# Удаляем слово by
- normalize:
routine: replace_substring
args:
^by\s+: ''
- object_field_set:
object: item
field: brand
# Собираем рейтинг
- find:
path: span[aria-label]
slice: 0
do:
- parse:
attr: aria-label
filter: ^([0-9\.]+)
# Проверяем, есть ли данные по рейтингу
- if:
match: \d+
do:
- object_field_set:
object: item
field: rating
type: float
# Собираем количество отзывов
- find:
path: span[aria-label]
slice: 1
do:
- parse:
attr: aria-label
filter: (\d+)
# Проверяем, есть ли данные по отзывам
- if:
match: \d+
do:
- object_field_set:
object: item
field: reviews
type: int
# Собираем цену
- find:
path: span.a-price > span.a-offscreen
slice: 0
do:
- parse:
filter:
- ([0-9\.]+)\s*\-
- ([0-9\.]+)
- object_field_set:
object: item
field: price
type: float
# Собираем prime
- register_set: "no"
- object_field_set:
object: item
field: prime
- find:
path: i.a-icon-prime
do:
- register_set: "yes"
- object_field_set:
object: item
field: prime
# Собираем количество продавцов
- find:
path: a:contains("new offers")
do:
- parse:
filter: (\d+)
- object_field_set:
object: item
field: sellers
type: int
# Собираем ссылку на изображение
- find:
path: img.s-image
do:
- parse:
attr: src
- normalize:
routine: replace_substring
args:
\.[^\.]+\.jpg: '.jpg'
- normalize:
routine: url
- object_field_set:
object: item
field: image
- object_save:
name: item
# Второй темплейт
- find:
path: li.s-result-item
do:
# Парсим аттрибут data-asin чтобы получить ASIN продукта
- parse:
attr: data-asin
# Проверяем наличие ASIN в регистре
- if:
match: \w+
do:
# Создаем новый объект данных
- object_new: item
- object_field_set:
object: item
field: asin
# Давайте тогда сгенерируем URL на страницу продукта
# Сохраняем ASIN в переменной
- variable_set: asin
# Пишем в регистр значение и записываем URL в объект
- register_set: https://www.amazon.com/dp/<%asin%>
- object_field_set:
object: item
field: url
# Собираем имя продукта
- find:
path: h2
do:
# Удаляем флаг Sponsored из названия
- node_remove: span.a-offscreen
# Парсим содержимое блока
- parse
# Нормализуем пробелы
- space_dedupe
# Отрезаем пробелы с конца и начала
- trim
- object_field_set:
object: item
field: title
# Собираем бренд
- find:
path: div.a-spacing-mini:has(h2) > div.a-row > span
slice: -1
do:
- parse
# Нормализуем пробелы
- space_dedupe
# Отрезаем пробелы с конца и начала
- trim
- object_field_set:
object: item
field: brand
# Собираем рейтинг
- find:
path: i.a-icon-star>span
do:
- parse:
filter: ^([0-9\.]+)
# Проверяем, есть ли данные по рейтингу
- if:
match: \d+
do:
- object_field_set:
object: item
field: rating
type: float
# Собираем количество отзывов
- find:
path: div.a-spacing-none:has(i.a-icon-star) > a.a-size-small
do:
- parse:
filter: (\d+)
# Проверяем, есть ли данные по отзывам
- if:
match: \d+
do:
- object_field_set:
object: item
field: reviews
type: int
# Собираем цену
- find:
path: span.a-offscreen
slice: -1
do:
- parse:
filter:
- ([0-9\.]+)\s*\-
- ([0-9\.]+)
- object_field_set:
object: item
field: price
type: float
# Собираем prime
- register_set: "no"
- object_field_set:
object: item
field: prime
- find:
path: i.a-icon-prime
do:
- register_set: "yes"
- object_field_set:
object: item
field: prime
# Собираем количество продавцов
- find:
path: a:contains("new offers")
do:
- parse:
filter: (\d+)
- object_field_set:
object: item
field: sellers
type: int
# Собираем ссылку на изображение
- find:
path: img.s-access-image
do:
- parse:
attr: src
- normalize:
routine: replace_substring
args:
\.[^\.]+\.jpg: '.jpg'
- normalize:
routine: url
- object_field_set:
object: item
field: image
- object_save:
name: item
Пример датасета: Датасет Amazon